

When the internet first dawned, HTML was king when it came to building websites. This simple coding language was used to develop websites of all kinds, but it was just that: a simple language.
In the late 1990s and early 2000s, website development moved from simple infographics and text to high-powered interactive graphics like videos and usable tables, especially with eCommerce’s growing prevalence and necessity. This new era of web content demanded a more powerful programming language that could provide users with an enhanced experience.
Enter: JavaScript
Today, JavaScript, also called JS, is the most popular web development language. Of the 1.5 billion websites globally (and counting), JavaScript is used on more than 95% of them. It powers everything from animations and page navigation (and the plethora of individual tabs nestled under each page) to running the whole show (JS platforms), and everything in between.
The power and versatility of JavaScript is immense, but it comes with its own limitations. Namely, search optimization complications.
The simpler your website content is, the easier it is for Google or Bing to render and index everything on your pages. When you start to layer in interactive elements like visual animations, navigation, and eCommerce facets and filters, you ask Google’s robot web crawlers to do heavier lifting as they work to render and index your website in search results.
The problem, essentially, is that Googlebot isn’t inherently just going to do that extra work.
If you want to make sure your website content is fully rendered and indexed, you need to proactively audit your website for JavaScript errors and accessibility issues. Identifying and fixing these problems ensures that Googlebot is able to access all the content on your website. Failing to identify and correct these errors can result in some - or most - of your website content being inaccessible to Googlebot.

This article aims to walk you through the steps of running a JavaScript audit for your SEO. To do this, we first need to define a few key terms used in discussing JavaScript SEO audits, as well as the process Googlebot uses to crawl your website in its journey of returning search results for a user's query. Once you understand these terms and this particular SEO QA process, you will be better positioned to avoid those issues that might impact your SEO results.
Critical Terms for JavaScript SEO
There are a handful of terms worth grasping as it pertains to JavaScript SEO. These include:
- Crawling - the process by which web “crawlers” (Googlebot and Bingbot are most common in the U.S.) scan your web pages for relevant content to return in the search results for a user’s inquiries. Learn more about Crawling & SEO.
- Indexing - the ability of individual web pages to be discoverable on Google or the search engine of your choice. Learn more about Indexing & SEO.
- Rendering - where the loading of your JavaScript content takes place. The two primary options are:
- Client-side Rendering (CSR) means that the burden of accessing your JavaScript content is on the user. This can be your visitor’s browser (Chrome, Firefox, IE) or web crawlers.
- Server-side Rendering (SSR) means that your website’s server is responsible for loading your content for your users.
- There are also hybrid options for rendering. Each option has its pros and cons for SEO, site performance, and overall business needs. The two most important are Dynamic and Isomorphic rendering, discussed in greater detail below.
Dynamic Rendering serves fully pre-rendered content to search engines as static-rendered HTML while providing normally rendered content to users. Because content can be crawled without needing to execute JavaScript, the benefit of dynamic rendering is that it requires less time and resources, which is ideal for massive websites where hundreds of thousands of URLs need to be crawled and indexed.
Isomorphic Rendering also uses pre-rending to serve content to search engines or users, however interactivity required on JavaScript is executed via the client-side. Typically preferred by SEOs and developers, isomorphic apps make it easier to maintain code while providing faster load speeds and better user experiences.
JavaScript Frameworks
JavaScript is not a one-size-fits-all programming language. JavaScript in its most basic form, or "Vanilla JS," can be quite cumbersome. That’s why teams of developers will create either libraries or frameworks. In doing so, they take some of the more commonly used code and create pre-written code blocks and shorthand methods to save time.
To understand the difference between JavaScript libraries and frameworks, think of libraries as car accessories that can be added to any car of any model. Meanwhile, frameworks should be understood as the car itself. Ultimately, you’ll have a vehicle that can do many of the same functions as other cars on the road - but still has some inherent differences in how they function.
Frameworks are definitely causing the most excitement within web and software development - but also pose the biggest challenges for ensuring SEO is well-executed, technically speaking, at each step. There are three main JavaScript frameworks in use across the internet today: React, Angular and Vue. However, there are dozens, if not hundreds, more out there.
React
React JS is an open-source JavaScript framework used for building front-end user experiences (UX). It is primarily used for developers who are creating single-page applications (SPAs), and it’s especially useful when it comes to building mobile applications.
React was created by the developers at Facebook to help with the building of their own platforms. It’s also important to note that technically, React is a library and not a true-to-definition framework. However, it is becoming so prevalent in its use that this guide would be remiss to not discuss it.
Angular
AngularJS is a structural JavaScript framework used for efficiently building data-heavy, dynamic, and interactive websites. It allows you to lay your foundation using HTML and inject JavaScript to enhance and build out your website content.
Another technical note for just in case you run into a persnickety developer—Angular is actually based on TypeScript, a sort of evolution of JavaScript. The biggest difference between them is that TypeScript requires a compiler while JavaScript does not.
What does this mean for you? It means that your developers have better tools for error handling and debugging that don’t exist for vanilla JavaScript. So ideally, less issues and less QA time for you!
Vue
Vue.js is a progressive JavaScript framework that is used to build single-page user interfaces (UI) on both desktop-based websites and mobile applications. "User interface" or "UI" is a term used to describe back-end programming. This is the code that is running in the background of all the websites and applications you use.
Alright, now that you have a better understanding of JavaScript SEO terms and frameworks, let’s dive in.
Helpful JavaScript SEO Auditing & Testing Tools
If a JavaScript audit process sounds like a lot, it’s because it can be!
Luckily, you don’t have to do it all by yourself. There are several reputable and helpful JavaScript and SEO audit products that can do some - or all - of the heavy lifting.
We stockpiled a list of our favorite SEO tools that can help you with your SEO overall; for JS audit specifically, we like:

- Test Live URL Tool in Google Search Console:
- See real-time, Googlebot-rendered HTML, JS, CSS, etc. of a page by testing it, hitting View Tested Page, and navigating to the HTML tab. You can control+find your way to seeing exactly what Googlebot can (and can't!) see.
- See JavaScript errors in the More Info tab of the report in Page Resources and Console Messages.
- Rendering Difference Engine (browser extension): We built this Chrome Extension in-house to highlight discrepancies between response HTML and rendered HTML that impact how search engines crawl, understand, and index your URLs.
- View Rendered Source for Chrome (browser extension): See all code rendered into readable HTML - side-by-side with non-rendered HTML for easy comparisons.
- Wappalyzer, Web Developer (browser extension) or NoJS Side-by-Side (bookmarklet): For identifying and turning on/off JS, CSS, cookies, etc. for QA testing of what users and search engine bots experience in each situation.
- Inspect Element, View Source and Dev Console (browser tools): Steps on how to use these tools are outlined below.
- JS-enabled crawls: “How-to’s” outlined below. Oftentimes, you'll use these tools to see "previews" of pages as a search engine might "see" it.
3 Primary Causes of JavaScript SEO Issues
First and foremost, let’s address the elephant in the room (or on the screen).
JavaScript is not inherently bad for SEO!
In fact, when implemented correctly, JavaScript can support your SEO efforts just as much as hand-coded HTML. Even better, JavaScript can make for a more engaging experience on your site, adding to the quality of your website and content.
But when problems do surface, there are three primary sources of JavaScript issues for SEO, each with different ranking and indexing implications. We've broken these down below.
In simple terms (discussed in more detail below), the SEO problems that stem from JavaScript come when your website:
- isn’t allowing search engines "in,"
- isn’t giving them the correct/critical information, or
- isn’t making it easy enough (or worthwhile enough!) to make it worth the work to access those resources (all explained in more detail above.)
Each makes it more difficult (or impossible) for search bots to access your website and/or your website’s critical content. What’s “critical” to access?
- Unique, crawlable URLs which can be indexed.
- Data about and on each URL - specifically a page title, meta description, page copy including headers, and internal hyperlinks.
1. No Unique URLs Are Available to Crawl & Index (URL Accessibility Issues)

The first cause of JavaScript issues is pretty straightforward and found within your website’s URLs. In its base configuration, most JavaScript Frameworks don’t create unique URLs that are written so that they cannot be found individually (SPAs - I’m looking at you!) Instead, page content changes for the user, but the URL doesn’t change - much like when you use a mobile application.
To check if your URLs and the content is available and indexable, use a crawler like Screaming Frog or DeepCrawl to mimic a search engine bot, and create a dashboard of URLs & the data you found on them. This will tell you which pages are indexable, and which aren’t, and why that might be.
If URLs you know exist (and should be indexed!) aren’t found, that’s a problem, too.
2. Critical In-Page Content Accessibility Issues

The second cause of JavaScript issues is when search engine bots can’t find critical elements on your site/URLs. This could be due to a simple coding error or because it’s not being supplied to them.
It’s a relatively common issue for URLs to be available, but for the page copy, navigation links, and in-page content links to be hidden/inaccessible.
Both of these cases are full dealbreakers for SEO; even if Googlebot wanted to crawl and index your pages, your site quite literally isn’t structured to make that possible.
Another issue to keep in mind is that a single point of error can cause entire content sections to be inaccessible. That "error" could be Google opting to not render a single line of JavaScript. Learn more about the "Rendering Gauntlet" and how to avoid this issue.
3. Resource-Heavy Rendering vs Page Value Tradeoff

The final cause of JS issues has to do with your website’s rendering, especially if you are utilizing client-side rendering.
Generally speaking, it is less expensive (in terms of fiscal payments to your hosting provider) to utilize client-side rendering since it uses less server space and less programming.
However, this cash savings comes at a cost to your SEO efforts, as it passes the burden of accessing and loading your JavaScript content to search engines & users’ browsers.
Server-side rendering is a more expensive option both in terms of server space and programming hours. However, it can dramatically improve your JavaScript SEO efforts by taking the rendering burden off Googlebot’s rendering service - and off your user’s browser.
A third hybrid rendering option is also available (in fact, there are many variations!) But generally speaking, hybrid rendering and prerendering utilize both client-side and server-side rendering. It allows Googlebot to easily access your content through selective server-side rendering, while also utilizing client-side rendering for human access when SEO needs are less important.
The “cost” of rendering can mean timeout errors for Googlebot, OR it can simply create an unequal trade-off, wherein Googlebot decides that the value your page brings is too low to be worth the work of rendering, storing, and indexing it.
In this scenario, Googlebot can access the critical URLs and content - your site just makes it too cumbersome for Googlebot to bother in most cases. This isn’t inherently a “deal-breaker” for SEO - depending on the value of the brand as a whole and the page's specific purpose/value - but it is a real concern that can dramatically limit your ranking potential in many use cases. Learn more about why this is & how it could impact your site.
Which JavaScript Issues are Problematic for SEO?
Here are four main potential outcomes or scenarios that can help you in prioritizing JS issues:
Best-Case Scenario
The best-case scenario is that everything “shows up” without any errors. This is a good sign that Googlebot has full and immediate access to your content. This includes looking for navigation links being present, text content, images, and videos (they’ll be ugly, but that’s okay!)
Things you probably won’t see but that’s ok:
- Structured data that’s been implemented through JSON (JSON means JavaScript Object Notation, so it definitely won’t show up in a non-JS view)
- Content animation - but you should still see the content itself
- Background images
Maybe-Fine Scenario
This middle-to-sometimes fine scenario occurs when all important content is accessible for search engines, and upon rendering, everything shows up correctly. (e.g. the work of rendering falls to search engines.)
The challenge here is that you are making Google (and other SEs) do all the heavy lifting in understanding and rendering JavaScript-based content. This generally means that they won't do it if and when they don't want to, given that it takes an estimated 9x the time to render JS vs. HTML.
When will they want to? When the overall site, and the specific page in question, warrants that additional work.
When won't they? When they don't see the need to; e.g. when other resources - perhaps with more valuable backlinks, or better content - already cover that same subject "well enough".
Do note that in many cases, this is absolutely fine. We simply encourage you to ensure that your site as a whole, and your individual pages, are as high-quality as possible. Otherwise you may run into the dreaded "Crawled but not indexed" errors in GSC.
Middle-Case Scenario
The middle-case scenario is that some, but not all, content shows up in your source code, with or without errors. The errors you might see at this level is likely a reflection of your rendering. While your content may show up in Google’s rendered code, it still needs to be rendered. This could be causing Googlebot to be unable - or unwilling - to access your content at the time of the crawl.
The types of content that we usually see fall in this space:
- Accordions / Tabs
- Sliders*
* Please, oh please, just stop using sliders. And on that note, accordions or tabs are NOT always the solution to long pieces of content. Stop making the user work harder to consume your yummy content!

Middle-to-Sometimes Bad Scenario
A middle-to-sometimes bad scenario is when there’s no content showing up in the source code, but Googlebot can access all/some critical elements upon rendering.
This is generally the case when working with JavaScript website with the default state of client-side rendering. While potentially not the end of the world, it’s certainly less than ideal.
Worst-Case Scenario
The worst-case scenario is that your content does not show up in your source code AND is not visible to search engines upon rendering. This means that Googlebot is not able to access your critical JavaScript content.
How can you double-check which scenario your pages fall into? By using the tools mentioned above (e.g. Mobile-Friendly Tool, rendered DOM vs. source code, browsing with JS turned off), you can usually get a clear view into the severity of the problem at hand. When critical elements are entirely missing, it's usually a bad- to worst-case scenario that should be considered a high priority.
However, you might be pleasantly surprised to find that Google is seeing everything correctly since it can in fact render JavaScript (usually...) Knowing whether the content in question is fully invisible to Google, or maybe just not as pretty, is extremely important when troubleshooting (and prioritizing) JavaScript problems with your development resources.
SEO JavaScript Auditing 101: How to Identify JavaScript SEO Errors
Too often, JavaScript is implemented in such a way that it’s harder for search engines to do their jobs. That’s - quite literally - the antithesis of technical SEO work. We work very hard to make content easy to access and worth accessing - so any barriers to that naturally create bottlenecks.
To make sure your website is free from these problems, you need to know how to find, identify, and fix your JavaScript errors and issues. Let’s take a look at how to do that now.
Step 1 - Preparation: Identify Your Tech Stack

Before you can really start understanding how JavaScript may or may not be working for you, you have to make sure you know what technology is making the site happen. This involves a combination of programming languages, frameworks, and tools used to build your site or app.
For this, we suggest using a Chrome plugin called Wappalyzer. This tool can help you determine if the site is using React, Angular, and a whole slew of other technologies that could be ultimately affecting the crawlability/renderability of your website.
Understanding your stack will help you better identify what and how much (e.g., to what extent of) auditing is needed.
There are two primary scenarios to consider in identifying your tech stack.
- Your site is an SPA (single-page application) or a JavaScript App. In this scenario, more extensive auditing of the entire page is required via the following steps outlined below.
- Your site is NOT either one of these, and instead is some other non-JS platform (e.g. it's Wordpress, Joolma, Shopify, etc.) In this case, your auditing efforts will generally be more limited to interactive elements.
Wappalyzer is effective in generally uncovering your site's technology stack, including the CMS, Frameworks, or Programming Languages being used. If you're unfamiliar with the information revealed, a simple Google search is recommended.
If one of the categories says "JS Library," you can safely deduce that it is, in fact, a JS site. However, in the cases of the latter scenario (non-JS nor SPA), a visual inspection of interactive elements via the bookmarklet may suffice.
Sitebulb's Website Auditing Tool is another great way to identify the tech stack, perhaps as a part of your normal SEO auditing process:

This report actually leverages Wappalyzer to pull this data, and is available when you use the Chrome Crawler in Sitebulb.
While above scenarios are foundational variables, there are a number of other technologies that can affect crawlability. Some of these include, but are not limited to:
- Video platforms/embeds
- Analytics tools
- GDPR/CCPA compliance tools
- Chatbots and interactive agents
- Advertising pixels
- Web server errors and misconfigurations
- Outdated design technologies, like Flash and HTML frames
Once you have a clear picture of what your tech stack looks like, the next step is to roll up your sleeves and start auditing the JS issues plaguing your site’s SEO.
Step 2 - Site Audit: Macro JS SEO Issues
Now that you’ve verified that your site is, in fact, using JavaScript (and let’s be real, pretty much all modern websites are), the next order of business is to identify global issues that can be fixed at scale.
Start by running a site crawl with JavaScript rendering enabled. Some favorite tools of ours to do this are Screaming Frog, Ahrefs, and Sitebulb. Check out each tool’s documentation for how to enable JavaScript rendering (seriously, they tell you how to do it much more efficiently than we can).
Typically, these crawl reports will show you more immediate issues, such as:
- 404 status codes not being served from your SPA - meaning Google just sees lots of soft 404s and very unoriginal content
- redirects being handled at a page level instead of at the server request (i.e. JS redirects and meta refresh redirects) - so basically if you have redirects to help with passing page equity, hah, kiss that goodbye
- metadata is missing and/or duplicated multiple times
- canonicalization is nowhere to be seen
- the robots.txt file blocks JS, image or CSS files
- orphan pages, or pages with low inlinks - because internal linking don't include proper <a> href tags

The goal behind this first audit is to identify big-picture issues that can be resolved globally. In some cases, you'll be able to pinpoint problematic macro patterns that you can dig into more granularly in the next step.
Pro Tip: The new version of Screaming Frog - 16.0 - has new enhanced JS crawling and free Data Studio dashboard template you should absolutely check out:

One last PRO TIP here: don't panic if you see 307 (temporary) and 308 (permanent) status codes - these redirect types are of growing popularity.

Step 3 - Page Audit: Micro JS SEO Issues
The intention behind this step is to visually analyze and investigate issues at the page level. To get started, you'll want to determine the critical pages to prioritize auditing. These are typically your most popular/top-performing pages as well as an example page of each major template/layout type.
For example, you'll most likely prioritize your homepage, category and product detail pages (for eCommerce), contact page, blog post, and any other pages built around critical templates that should be examined (generally 3-8 example pages, depending on the size of your site). Make sure you include any specific pages with lots of interactive functionality, as that’s where issues often occur. While there may be some overlap, the main idea is to better understand how each template/content type and resulting code is functioning, both with and without JavaScript.
Once you've determined the top-performing pages and critical templates driving your site, the next phase is to audit those pages and document any issues that you find in the process. How you do so can vary, but we recommend the three following tools for this stage:
Mobile-Friendly Tool
Scan a URL using Google's mobile-friendly tool and select the HTML tab. Review Googlebot rendered code with the question "can Google access this critical content?" in mind. Ideally, all critical elements should be present and thereby accessible to Google. But if you don’t see it here ("it" being critical SEO elements like copy, internal links, markup, etc.), then neither does Google. You can use this insight to dig into what's not showing, and why that might be.
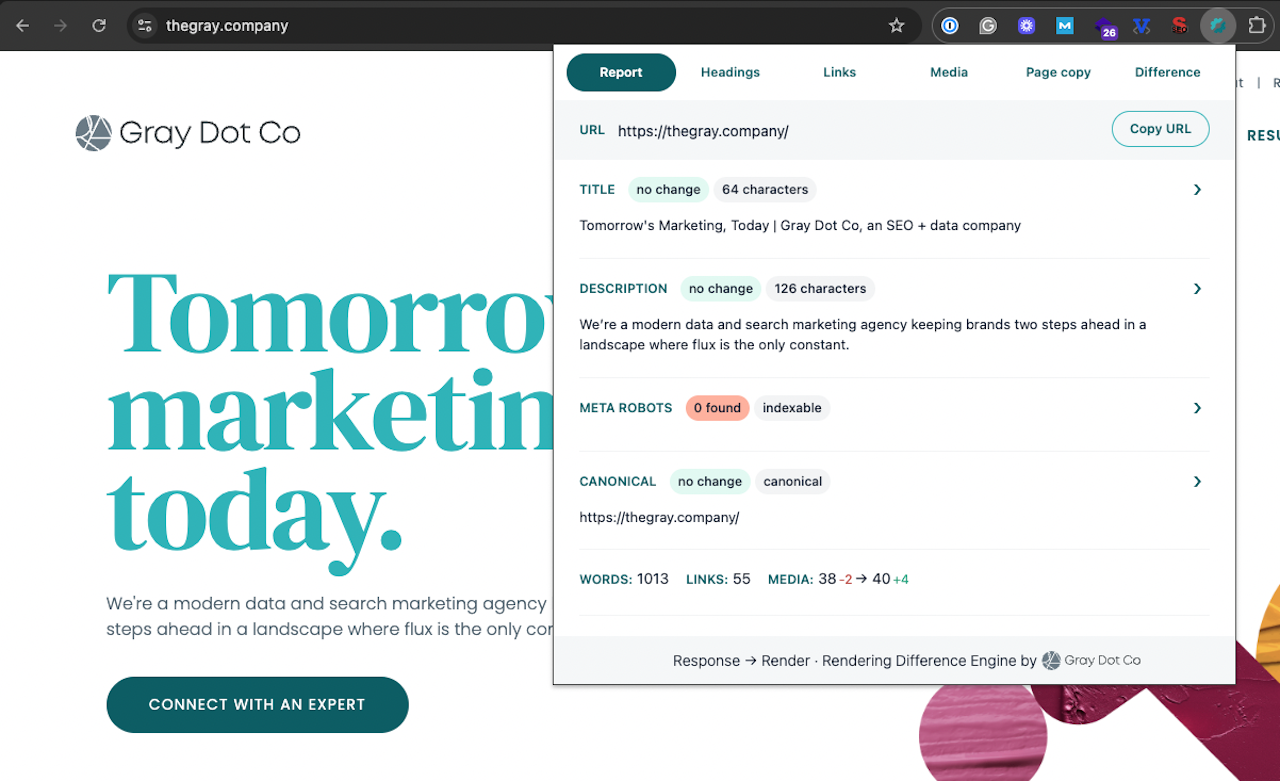
Rendering Difference Engine
Our home-grown JavaScript SEO Auditing extension enables you to compare a page's source code vs browser-rendered HTML, highlighting SEO-important discrepancies in just one click.
Browse Pages with JavaScript Turned Off
Another popular way to run this comparison is to “turn off” JavaScript within your browser. While there are tons of ways to do this, we recommend using this booklet so that you can actually see the page with JavaScript and without, side-by-side. This makes it much easier to pinpoint differences in content.
These tools are not mutually exclusive, nor do they all have to be utilized at this stage. You may simply prefer one tool over the other, and use it heavily, while bringing in one or another tool on an ad-hoc basis for additional information (e.g. when you know something is wrong, but you just can’t figure out what or why with the initial tool.)
Step 4 - (Optional) Troubleshoot JS SEO Issues
In the process of auditing JS SEO problems through the steps above, you'll likely identify issues that need to be documented and fixed. This may involve passing your findings along to a development team, which means providing clear information behind the what, where, and why of the issue.
This troubleshooting step is designed to equip you with the tools and processes needed to effectively pinpoint and communicate the JS issues impacting your SEO. Depending on your engineering team, however, this step may not be required.
Inspect Source Code vs. Rendered DOM
By referring to both a page's source code and rendered DOM, you'll be able to better define and articulate discrepancies that are causing problems. Here’s what that means:
Source code: When you “View Source” while on a browser, you’ll get the HTML that was delivered to the browser initially. This is referred to as the “source code.”
Rendered DOM: Use the ever-popular “Inspect Element” tool set or just open up your Dev Console (we recommend Chrome, as it’s the most popular browser). Also known as the “rendered HTML,” this will show you how the browser has interpreted that HTML, and perhaps even applied fixes that need to be made.
Coming Soon: All About Inspect Element & Troubleshooting for Site Issues and SEO.
You’ll typically want to do this for any interactive elements on the page (e.g. drop-down menus, tabbed content, and the like), and/or any elements or sections that you identified as problematic in Steps 2 and 3.
Some of the most commonly applied fixes that you should look out for include:
- missing closing tags (in HTML or JavaScript code) that can disrupt crawling
- syntax errors like simple misspellings or missing quotation marks in the code
- links that users see on the page but are missing from the rendered HTML
- interactive elements like drop-down menus, tabs, and accordions that "hide" critical copy, info, or links
- lazy loading content that should be fully crawled and indexed, such as core page copy
- animations using JavaScript, which are expensive on performance compared to native CSS Animations
- unused APIs, which can be very costly on processing power
- canonical tags and/or meta tags that don’t match your expected responses
These are just a handful of overarching problems we often come across. For a related read on this topic, see other common JS SEO issues and how to overcome them. In the next step, we discuss more about prioritizing fixes and communicating them to your engineering team.
Step 5 - Prepare Issue Insights for Engineering Handoff
Based on your findings, you'll want to prioritize issues by the importance of page type AND the criticalness of what’s missing. For example, random JS errors are far less detrimental than Googlebot not finding product page links from category pages on a webstore (as that’s the core purpose of that page, and without it, Google can’t easily find or pass page rank to the products you want to sell). Utilize the JS SEO Issue Scale outlined above in determining how big of an issue the actual JS error itself is.
This prioritization process is part one of two, with the second part focusing on what to convey to your engineering team. Assuming you're not handling fixes independently, the next crucial step in your JavaScript SEO audit is communicating what's missing, where, and why it matters to the business. Doing this on a template level can make it more efficient for web developers to fix problems found on critical templates/layouts and top-performing URLs.
Content Function Bucketing
In addition to prioritizing which fixes need to be made first - on what pages (or page templates), it's very helpful to segment your content by function or type. For instance, you can use your audit's visual analysis and crawl data to organize content into the following four categories:
- Visible content, such as images, graphics, videos
- Interactive content, like customizable tables and filters
- Hidden content that’s only visible with user interaction, such as dropdown menus and accordions
- User-generated content, like customer and product reviews
This kind of content categorization can drastically reduce the amount of back-and-forth spent between developers and/or product managers. Often, the building blocks of JavaScript apps are designed by the function, not by the content itself. Organizing your JS fixes by content function can help tremendously later on when you need to ask your dev team for help.
This framework also helps in determining rendering issues based on layout features/functions, meaning you won’t have to audit every single page. Rather, you can typically just audit each module or presentation of content. In doing so, it helps to:
- Define actual versus expected user behavior
- Share toolkit for QA and confirmation of the fix
- Include troubleshooting details you may have outlined in step four
JS SEO Ticket Creation
The tickets themselves should be grouped by page and/or page type, and content function, as outlined above.

Like all good tickets you submit to your software development team, please ensure you include the following information:
- Prioritization insights
- A defined user story
- Steps to replicate the actual behavior (what you are seeing) vs expected behavior (what you should see when it’s fixed)
- Share the appropriate tools and links for QA testing (confirming that the fix is, in fact, in place)
- Optional: more troubleshooting details you may have outlined in step 4.
Once you're on the same page with your dev/engineering team, it's time to carry everything over the finish line and ensure it's fixed, and fixed for good.
Step 6 - Stage QA, Go-Live, Live QA and Performance Monitoring
This step is really about getting the fixes deployed, QA’d, and over the finish line.
Upon initial QA testing, note that you may need to pull in additional tools to help confirm a fix. Some tools - specifically the Mobile Friendly Tool - are only usable for publicly available pages (e.g. you can’t run it for non-indexable stage URLs.)
QA for Content Changes
Changes to high-priority SEO content should also be reviewed for quality assurance. Make sure that any new content a) still exists, and b) meets (or exceeds) your expectations based on what you’re seeing.
While it may seem obvious, specific items to make sure to check include: page titles and meta descriptions, Hreflang and internationalization features, on-page copy, internal links, images, videos, and other media types.
Performance Monitoring
Equally important as fixing problems is ensuring they don't surface again in the future. There are a few tools and measures we recommend to help with ongoing QA and performance monitoring.
- Post-Release Crawl - Your primary line of defense to verify that fixes are indeed in place
- Automated Weekly Crawling - Use SEO tools like Moz, Ahrefs, DeepCrawl, Semrush or your auditing crawler of choice to automatically notify you of new issues that arise on a weekly basis. Then pay attention to these emails and make fixes as needed.
- DeepCrawl - a powerful technical SEO tool that offers an automation hub that’s specifically useful in finding and resolving SEO problems.
- Google Search Console - Make sure you have your account established and that you receive notifications when things go awry.
- SEO Change Monitoring Software - SEO Radar, Content King, etc. can automate this process for you, for a fee.
Post-fix SEO quality assurance testing and performance monitoring isn’t rocket science. It just takes having the right toolkit and knowing where to look. While automating as much as you can never hurts, referring back to your initial auditing tools is often a fail proof way to manually test for high-priority ticket items.
Takeaways
JavaScript is the most commonly used language when it comes to building high-powered, interactive, and visually appealing websites. And yet, there's no denying that JavaScript can be an elusive SEO “problem child” when it comes to crawling and indexing your site's content.
The more you can grasp the nuances of JavaScript SEO and how to best work with JS-generated content, the more you can mitigate the occurrence of big problems. Remember, incredible user experiences are good for your SEO strategy. But it’s not uncommon for JavaScript to disrupt your SEO efforts by blocking Google’s ability to accurately and fully render and index your site.
To combat these problems, you need to routinely audit your website for JavaScript errors inside the source code, especially when you create new content. You should also evaluate the pros and cons of rendering options to determine which one is most beneficial to your site’s SEO efforts.
Remember, you are not alone in the world of JavaScript auditing. There are many affordable tools and resources to help point you in the right direction. We’re always here to help and guide your team as needed.
Need Some Help?
Looking to get to know the vast neighborhood that is SEO, in all its forms and functions? We’d love to show you around. At The Gray Dot Company, we specialize in working as partners and external consultants with various types of SEO and digital marketing teams, and we provide advanced capabilities and experience in the complex realm of technical SEO.
Contact us today for a friendly conversation that will help us better understand your JavaScript SEO needs and how we may best serve you on your journey to SEO success.
