
I got a fun question from a client, who asked me to name the single, most common technical SEO problem that we run into when working on sites.
Without having to think too hard, I answered pagination.
Pagination SEO problems pop up with shocking consistency across sites big and small, impacting crucial elements like listing discoverability, link equity, and site crawlability.
The interesting thing about that is pagination’s anything but new. In fact, it’s one of the most tenured pillars of SEO.
So let’s dive into what every SEO should know about implementing SEO-friendly pagination on any site.
Comparing pagination vs. Infinite Scroll vs. Load More
At heart, pagination in SEO focuses on how a site serves listing page results, like products or articles, to its users. When there are a lot of listings, sites usually load the results in increments. Pagination, Infinite Scroll, and Load More are the three main methods of loading listings in UX-friendly increments.
What is pagination?
Pagination on a website is something that we’re all pretty familiar with because it’s about as old as HTML itself.
You see it on different types of listing pages where there are many results, whether they be products, blog articles, UGC, videos, or other types of resources.
The results are split up into consistent increments over a sequence of numbered pages. On each numbered page, there’s usually a link to the next and previous page of results. In many cases, there are also links to a range of individual page numbers.
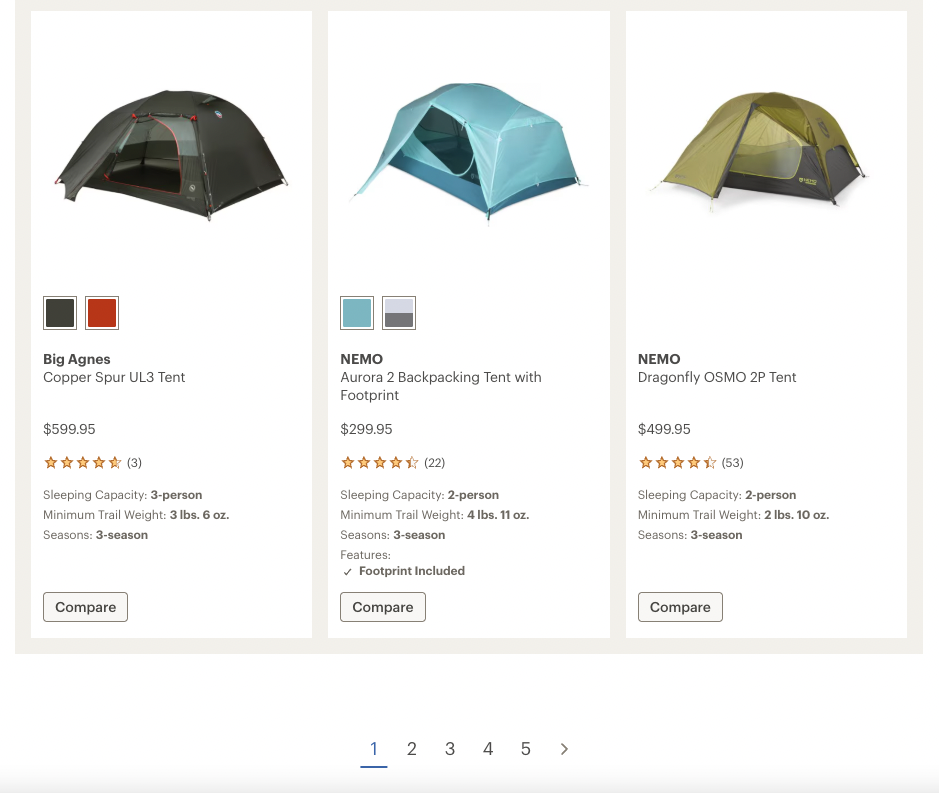
Is pagination good for SEO?
Pagination that’s set up correctly is great for SEO! For large sites, it might even be crucial.
When it’s well-optimized, search engines can crawl links to listings on each page of the sequence. That means they can use those links to discover new pages and pass PageRank from the listing page(s) to the linked pages.
However, there are a number of ways to set up pagination that aren’t accessible to search engines. If SEO considerations aren’t part of the implementation, there’s a good chance it will result in SEO issues.
Most sites implement pagination via JavaScript, whether the site is on a JS platform or not. It’s easier to implement with existing toolsets and makes it possible to load additional results on the same page in a performance-friendly way. But in many cases, bots like Googlebot can’t find or crawl those links.
What is Infinite Scroll pagination?
Infinite scroll is a method of loading additional results once users scroll further down a page, often employing mechanisms like “lazy loading” or “incremental loading” for speed.
When brands choose Infinite Scroll over traditional paginated pages, it's generally a UX decision. It doesn't require an active user action, since it loads on a scroll versus a click, which is less "work" for the user. That’s typically better for engagement and keeping users on the site, but not as effective in terms of driving product views and purchases.
Plus, the UX is often preferred on mobile, rather than asking users on a smaller screen to click tiny links at the bottom of the listing grid. That’s why even brands that choose traditional pagination on desktop often choose an Infinite Scroll implementation for the mobile experience. (Yes, it can be different by device!)
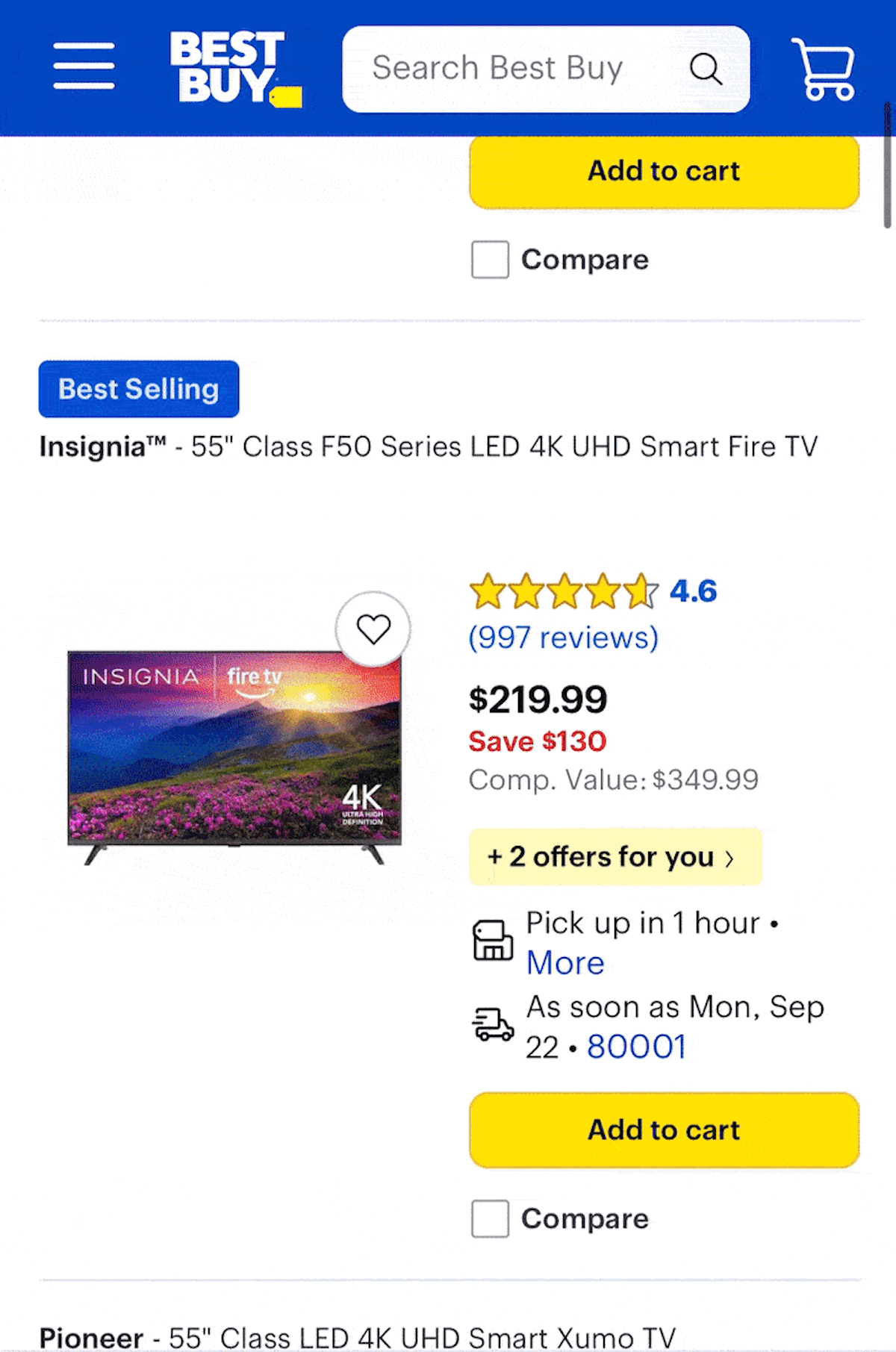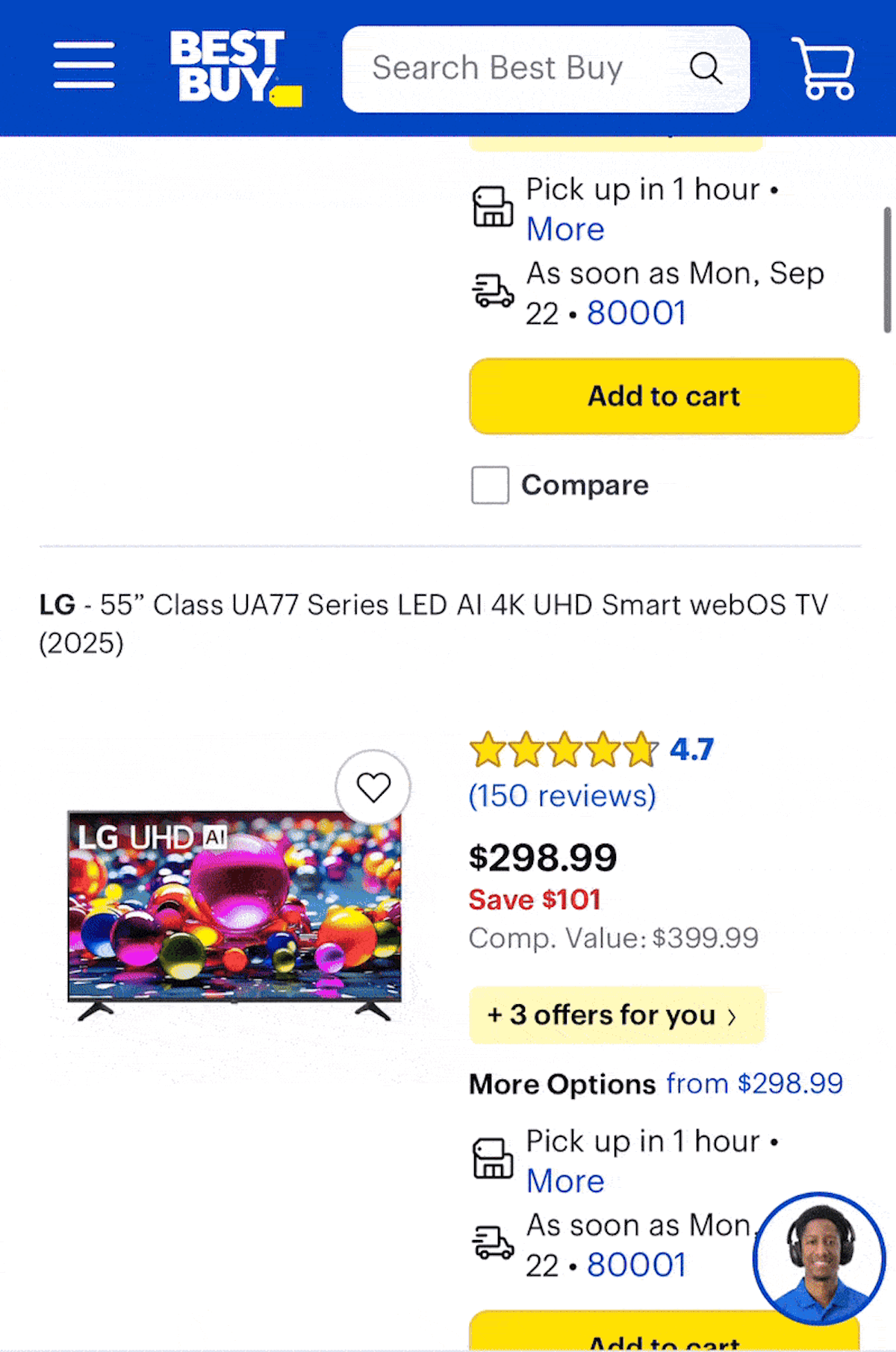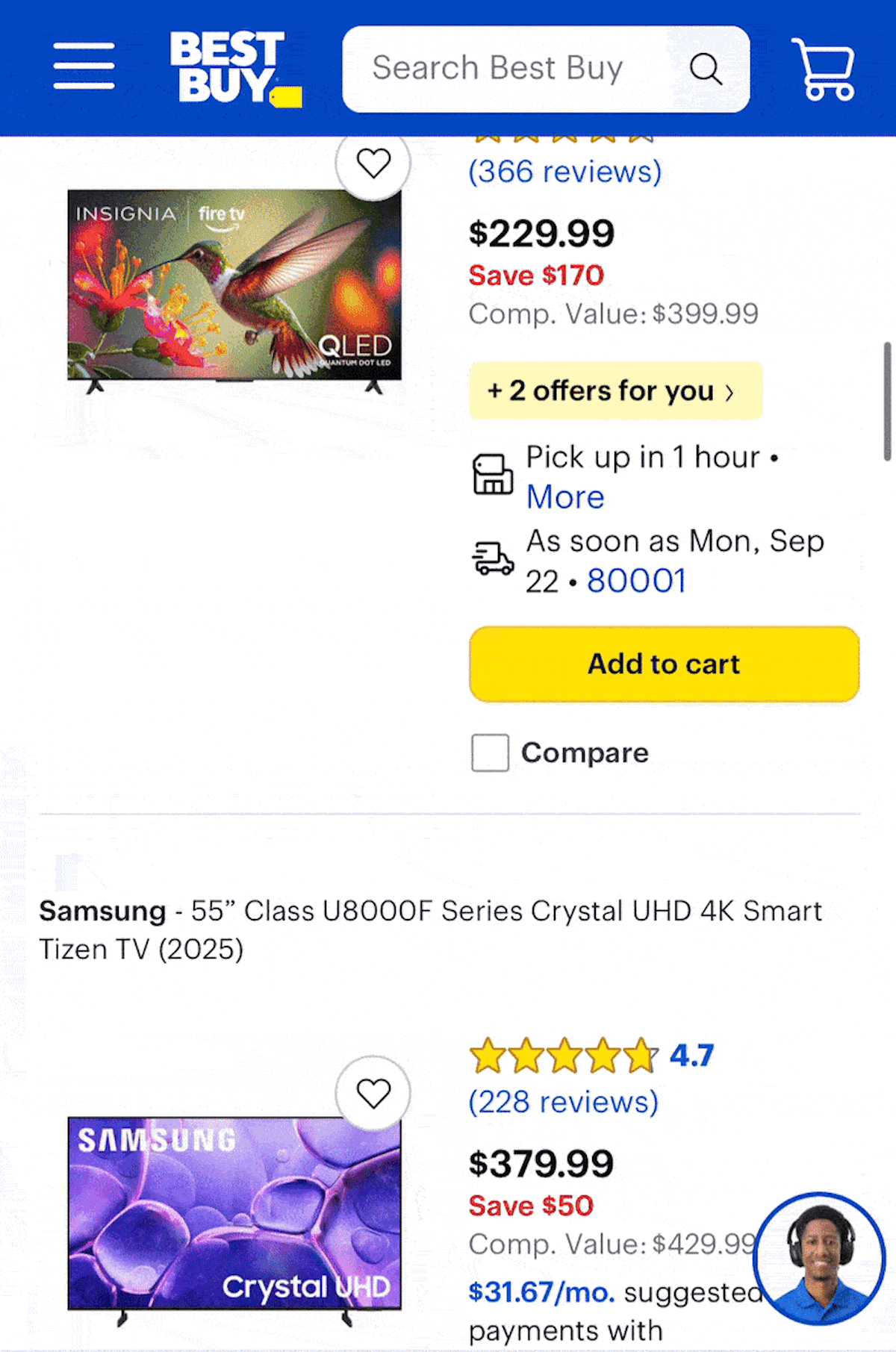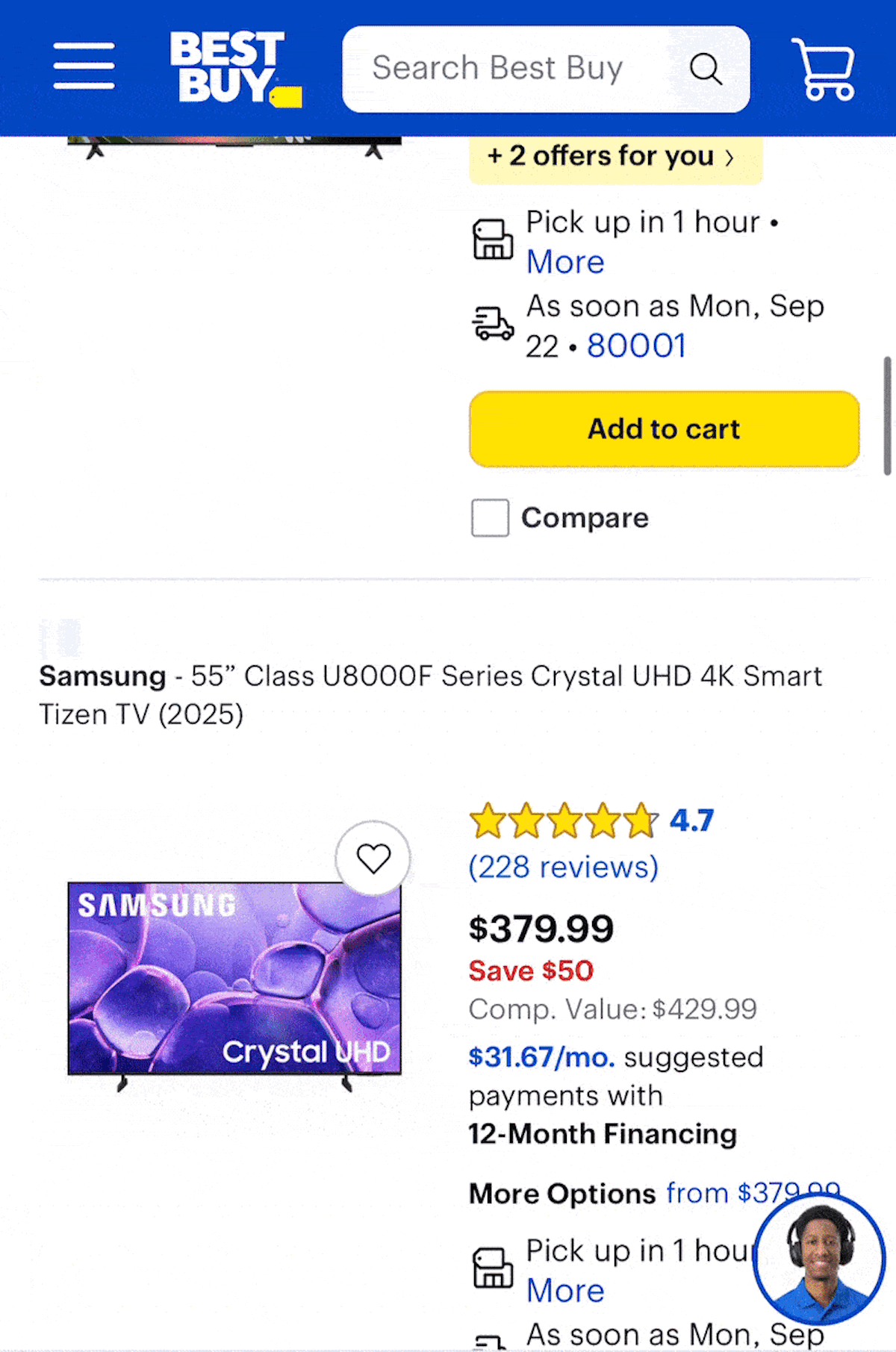
Is Infinite Scroll good for SEO?
There’s no reason to avoid Infinite Scroll from an SEO standpoint. In fact, Google has gone so far as to say users seem to prefer single-page experiences versus multiple pages — at least in some situations.

The main SEO issue that pops up with Infinite Scroll is that a user interaction (scrolling) triggers JavaScript to load more results, but crawlbots like Googlebot can’t interact with a page like a human user.
That means they can’t scroll down the page to see links that aren’t initially loaded. They can only crawl and follow <a href> links that are included in the code.
When sites have Infinite Scroll SEO issues, it’s often because the actual links are absent.
What is Load More pagination?
Load More pagination is quite similar to Infinite Scroll pagination. The main difference is the user action that triggers more listings to load: clicking a large “Load More” button versus scrolling past a certain point of the page.
This is why some SEOs consider Load More a specific implementation of Infinite Scroll. However, it’s worth noting that Load More is entirely different from a development standpoint. It’s different UX and built using different libraries, even though they share similarities.
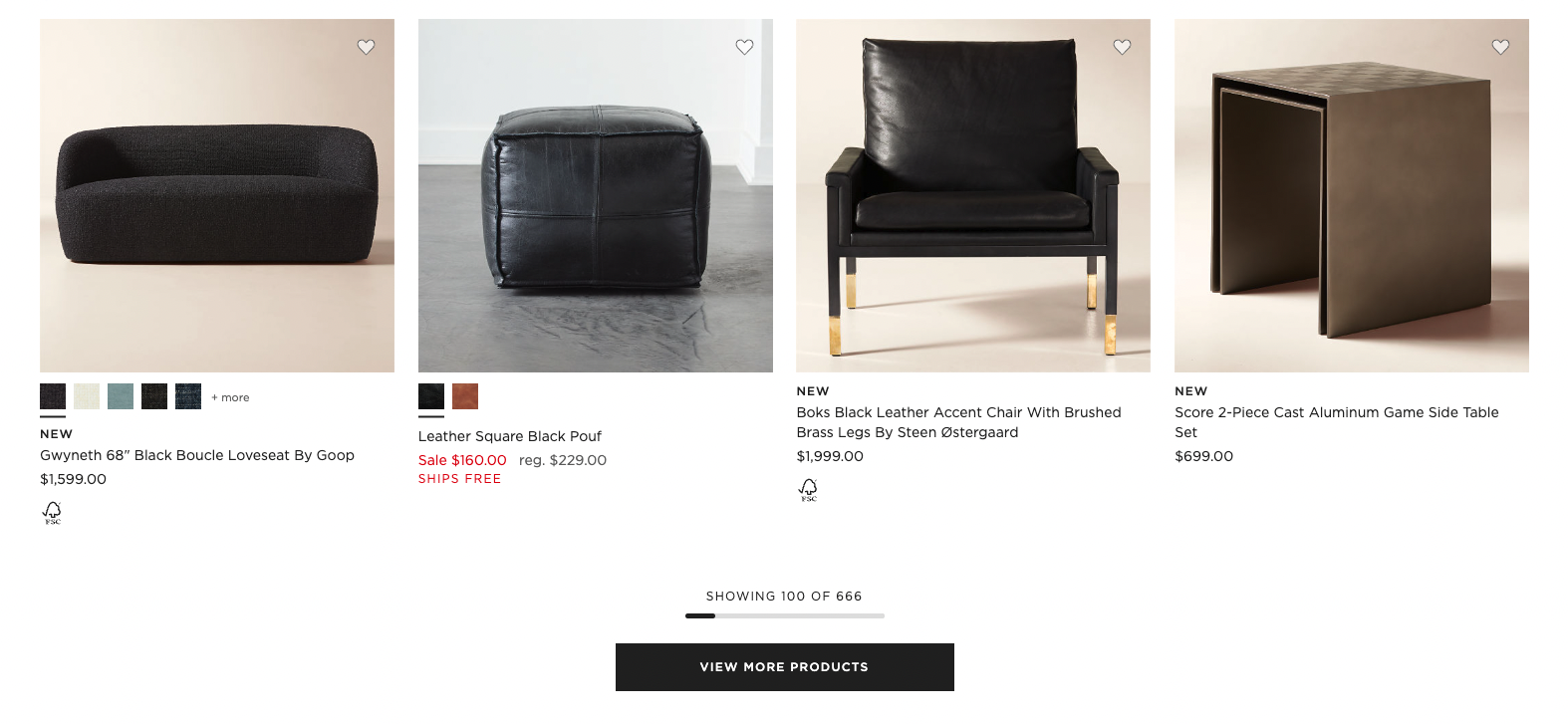
Is Load More good for SEO?
The same potential SEO issues that apply to Infinite Scroll also apply to Load More pagination. It takes additional dev work to ensure that search engines can crawl links to pagination URL variants.
That usually isn’t the case in the default implementation. HTML buttons are not links by default.
However, links can absolutely be styled as buttons to achieve a Load More look and feel, while meeting SEO requirements for crawlability. We’ll get into that as we chat through pagination best practices.
Is Load More, Infinite Scroll, or pagination better for SEO?
It quite literally does not matter which UX solution you select, so long as the way it’s implemented in HTML meets SEO pagination requirements.
In all three cases, the goal is ultimately the same: make sure that all the different elements of your listings are in HTML that crawlers can access — especially links! Since that’s usually not the case in the fresh-out-of-the-box implementation, it takes some behind-the-screens tech work.
Beyond that, this is more of a UX question than anything else. What keeps your users on the site, interacting with, and purchasing your products best? Test and find out.
Remember: Keeping users on the site is great for SEO!
Pagination Best Practices for SEO
These guidelines for SEO-friendly pagination ensure that Google can find and follow links, so it can crawl, contextualize, and index URLs on your site.
Remember: We live in a mobile-first world, and in a large majority of cases, Google crawls mobile-first! So pagination needs to work correctly on desktop AND mobile. Again, It’s not uncommon to see pagination implemented differently based on the UX that makes most sense for the device.

1) Required: Give each page a unique URL.
Otherwise, bots won’t be able to crawl the individual pages in the sequence, find links on those pages, and pass PageRank to the linked URLs.
That’s true for both search-engine bots like GoogleBot, as well as those used by AI search platforms like ChatGPT, which uses a crawl agent called GPTBot.
Infinite Scroll and Load More setups often load listings on the same page for users. This UX is fine, so long as there are also unique URLs linked in the HTML for search engines.
Technical requirements
Use a valid pagination URL structure to serve each page in the sequence.
- Add a unique URL slug (ex: yourdomain.com/blog/page-2/).
- Or add a query string (ex: yourdomain.com/blog?page=2).
- Don’t use URL fragments, including hashes (#) and hashbang (#!) variants, as they aren't supported by Google.
- It’s fine if your platform produces “ugly” pagination URLs with parameters like /scarves?position=fb6jd8EK8, as URL names don’t impact rankings.
The parent URL should be the only URL for the first page of results.
- i.e. Given that /accessories/scarves/ exists, then /accessories/scarves/page-1/ should not exist.
- This is assuming that /page-1/ duplicates the same listings as the origin page.
- If this isn’t possible for technical reasons, the /page-1/ variant should indicate the parent URL as the canonical tag to avoid duplicate content.
2) Required: Link to each paginated URL.
Each page should link to other pages in the pagination sequence.
Note: The number of linked pages that is appropriate changes based on catalog size.
Technical requirements
Link to URLs in the pagination sequence using an <a href> tag.
- Google can’t crawl other link formats.

When linking to the first page of results, the URL should be the parent URL.
- Don’t link to a duplicate page that includes the page number (/scarves?page=1).
3) Required: Make sure Google can crawl and index each page of listings.
Like any valuable page, paginated URLs are only valuable if Google can crawl and contextualize the page.
Technical requirements
Don’t disallow crawling using robots.txt.
- Make sure there aren’t any rules for parameters or URL structures that would universally keep pagination from getting crawled.
If using a canonical, ensure that each item in the series is self-referencing.
- Don’t canonicalize page 2+ back to the parent URL!
- The true function of the canonical URL is to help Google manage duplicate or near-duplicate pages.
- Hence why it’s okay to canonicalize /page-1/ to the parent URL.
If using a meta robots tag, set it to “index, follow” for all URLs in the sequence.
- To be HYPER specific: don't noindex pagination page variants. Page 2 is a valid and unique page.
4) Recommended: Distinguish pages using on-page elements.
Avoid duplicative content and help search engines contextualize pagination by optimizing core, on-page SEO elements that you would for any page you want indexed.
Technical requirements
Include the page number to make each of the items below unique to the URL. Consider automating this on page 2+ of all listing pages.
Page title
- Example: Page 2 — Unique Scarves for Every Season | Spicy Scarf Site
Meta description
- Example: Page 2 — Fashion-forward scarves for every season and style, including stunning designs made from sustainable materials.
H1
- Example: Unique Scarves — Page 2
5) Recommended: Don’t load or link to pages that don’t have listings.
Sometimes you’ll run into an error where paginated URL variants are valid no matter which page number you type into the URL.
- For example, you might only have three pages of results, but ?page=43 yields a 200 status page that’s a page shell with no listings.
- These URLs are technically soft 404s and an area where Google might find and crawl a number of unwanted URLs.
Technical requirements
Ensure that only pages with results are valid, 200 status pages.
- Serve a true 404 header response code on any pages that don’t have results (and don’t link to these pages!).
Infinite Scroll and Load More best practices for SEO
All of the requirements that we just talked about also apply to Infinite Scroll and Load More implementations. However, since the user experience takes place on a single page, making either SEO-friendly means having a classic pagination structure behind the scenes.
There is still an <a href> link to the next page of results, developers are just able to use JavaScript to make those results load on the same page.
Common (and not so common) pagination questions
Recently, I posted a LinkedIn thread about pagination that turned into a great discussion. A lot of folks had pagination SEO questions that get at some of the more important nuances you likely won’t find in the average best practices list.
Do rel=”next” and rel=”previous” matter for SEO?
In 2019, Google stated that rel=”next” and rel=”previous” were no longer used in the indexing and ranking model. Today, it’s also obsolete for accessibility and assisted devices.
Bing still uses these signals for discovery, but beyond this aspect, it’s probably not worth the work to add.
That doesn’t mean that sites should remove them if they exist. They’re not hurting anything, so it’s just not worth the work that goes into removing them.
Do all pagination URLs need to be indexable?
While this is generally a good idea for most paginated series, there are clear exceptions.
Pagination variants are like any other URLs.
We need to assess whether they’re unique and valuable or not, based on the pages themselves and the URLs they link to. If not, they’re likely not that valuable from an SEO standpoint, and they might not need to be indexed.
The duplicate content exception
Tag and category pages on blogs are common examples of paginated content that don’t need to be indexable. Chances are your main blog series already has pagination that’s crawlable. Additional crawl paths to the same content have diminishing returns, while also duplicating the same title/description.
In most cases, they’re thin and duplicative pages that have the potential to hurt your SEO more than help it.
A crawl-budget caveat
On really big sites with hundreds of thousands - if not millions - of pages, the issue of crawl budget should play a role in how to think about indexing paginated variants.
For example, a HUGE eCommerce site might have pages and pages of product reviews for a single product. It may also have pages and pages of products.
But it might not have the crawl budget for both to be crawled frequently.
In this case, you might have to make tough decisions about what’s more valuable. It’s going to be smarter from both a business and SEO standpoint to make sure Google is crawling links from product listing pages (so it can discover products and pass PageRank), versus crawling additional reviews beyond page 1.
Is every link to a listing from a paginated URL valuable?
The goal is to make sure that you have crawlable links to each of your listings on the listing pages where users would expect to find them.
Once you accomplish that, additional pagination/links give you diminishing returns — especially when the linking page doesn’t have all that much PageRank to pass or a relevant parent/child relationship with the listing.
If you list a pair of pants in the product selection for your shirts collection, you’re not passing additional PageRank to the pants. You’re diminishing the quality of the product listing page by not aligning with user expectations.
What’s the right pagination UI for my site?
This really depends on the number of pages that are in the sequence. The more paginated variants there are, the more reason to have a more robust linking mechanism.
When there are only a few pages in the series, previous/next will cut it just fine. But if there are dozens of pages in the sequence, having only previous and next links is ultimately burying many pages several clicks deep. That’s likely going to lead to performance issues.
Where there’s pagination depth to warrant it, here’s how I rank the potential link setups from best to worst. (Note: Each should have previous/next links!)
- First few, middle, last few
- First few then last
- First few then middle or deeper (this is the Google setup)
- First few only
- Previous/next only
Is there any risk of page 2+ competing with or cannibalizing the parent URL?
This type of situation is really rare and typically only a concern for enterprise brands with legacy sites and SEO programs. Pagination is about as old as SEO and Google is generally really good at dealing with it.
If a paginated URL is outranking the parent URL for the sequence, then it’s likely that at least one of the following issues are at play.
Tech Issue
- Does the parent URL have a self-referencing canonical?
- If /page-1/ exists, does it canonicalize to the parent URL?
- Are there other reasons that search engines can’t crawl or index the parent URL? (e.g. Maybe JS SEO is changing the canonical and messing with signals?)
Linking issue
- Do external/internal links to listing pages link to page 2+ of the pagination rather than the parent URL?
- Only link to specific page variants from the parent URL and other URLs in the same pagination sequence.
- Are there links to the parent URL in priority placements such as the global navigation and footer?
Lack of context
- Do the title, meta description, and H1 of paginated URL variants indicate the page number?
- Is every paginated URL variant included in the XML sitemap?
- Removing everything but the parent URL from the sitemap should help Google understand it’s the priority page in cases where page 2+ are outranking it.
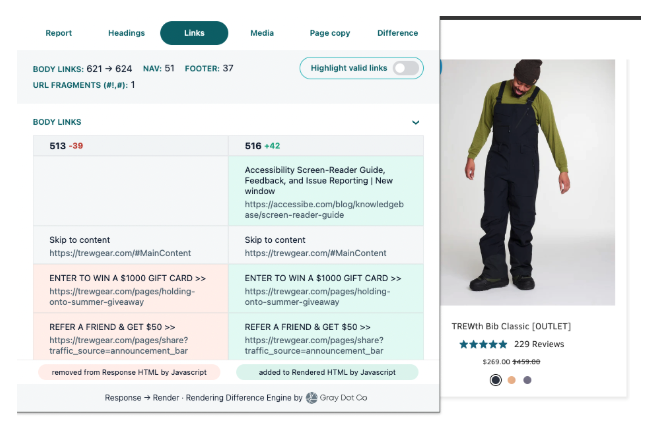
Does it matter whether links are in the response HTML or rendered HTML?
Google can crawl <a href> links in response HTML and rendered HTML, so both are valid implementations. But if the links are in the rendered HTML, it’s not a given that Google will do the work of rendering the page so that Googlebot can crawl the HTML.
That’s one of many reasons that I recommend serving key elements like links and copy as part of the HTML from the server response.
If you’re not familiar with how Google approaches rendering JavaScript or how it can potentially impact performance, here's the context you need.
Hint: Use our Chrome Extension, the Rendering Difference Engine, to see which links Google can crawl in the source and rendered HTML of any page.
If the link for a listing is missing from both columns, then search engines won’t be able to find it.
Build for users, optimize for SEO
Whether you choose Infinite Scroll, Load More, or traditional pagination with individual pages, you can optimize your setup for SEO. Like any major UX decision, pagination shouldn’t be driven by SEO alone — but SEO should be a voice in the room. No matter how you choose to approach pagination on your site, make your users the primary factor in your decision.
