

Looking into JavaScript issues is a little like playing doctor for your site: unless you can see something visibly broken, they most often don’t present in an obvious way.
Instead, it’s usually a process of starting with the symptoms, then connecting them to the most likely cause(s).
Over many years of optimizing SEO for JavaScript-powered sites across different frameworks, we’ve become familiar with the broad range of symptoms and the issues they indicate.
The most important thing we’ve learned? While JavaScript and SEO don’t always play nice, you don’t need to be a developer to render a diagnosis.
We’ll help map the symptoms that your site is experiencing to the most common issues we’ve seen behind each. Then, we’ll show you how to validate which are at play, understand what those underlying causes are, and how to make your JavaScript SEO-friendly based on the situation.
But first, just one question: Are you pretty familiar with how search engines crawl URLs and render JavaScript?
How does JavaScript affect SEO?
You can’t run a successful JavaScript SEO audit or implement best practices without understanding how search engines interact with JS in the first place.
For Google to decipher a page with JavaScript, it has to render the page. Crawlers can’t execute JavaScript on their own, so they call in the help of a rendering service.
The rendering process is complex and nuanced, but you can get most of what you need to know to investigate JS errors from this hyper-simplified breakdown:
- A crawler makes a server request - similar to a user visiting a page in their browser - and can quickly consume any page content and/or code returned in the response (“response” HTML).
- If and when JavaScript, APIs, etc. are identified on the page - e.g. any code which requires additional processing for interpretation - the URL is sent to the render queue.
- During rendering, the JavaScript and other code is parsed out. This may reveal additional page content for consumption by crawlers, or other page changes (we’ll get into that more below).
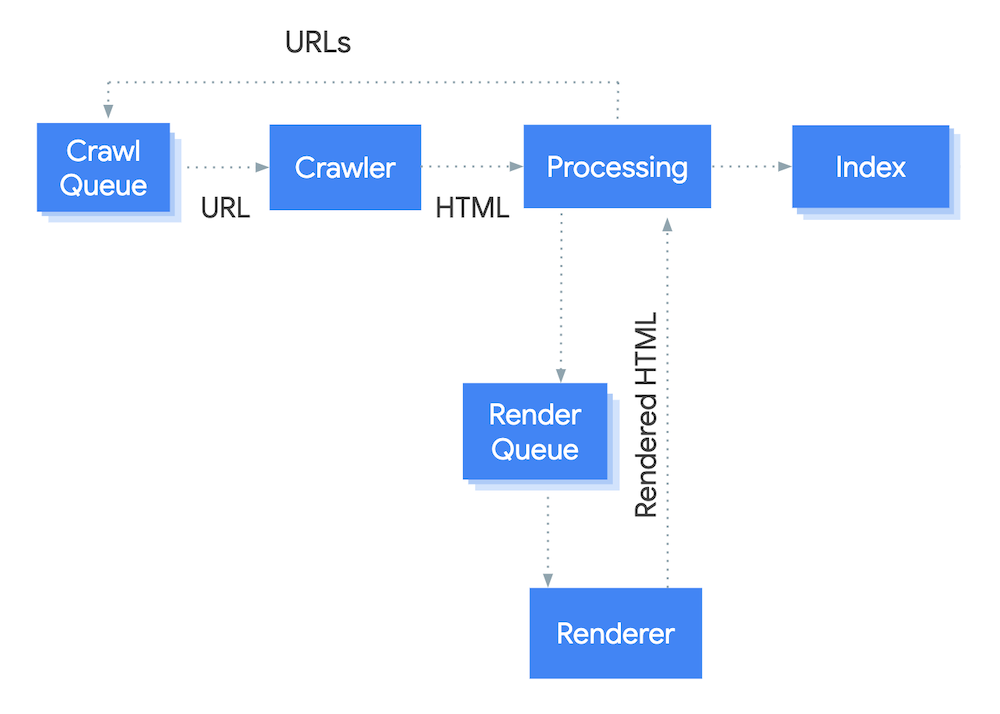
Key points for SEO
- Rendering is an extra step that requires more time, resources, and overall effort.
- Depending on how a site is configured, rendering happens at different points and the 'cost' falls on different services - which may mean your brand.
How do different sites handle rendering?
The two rendering options that are most popular represent the two different ends of what is actually a wide spectrum:
If a site uses server-side rendering, most or all page content is available to the crawler as part of the server response (response HTML). The “cost” of rendering is paid in advance by the brand without requiring more from Google (or other crawlers.)
If a site uses client-side rendering, most or all page content is only available upon rendering (rendered HTML). The cost of rendering is fronted by Google, which may result in reduced indexing and search visibility.
In between these two extremes are other configurations that make it possible to share the rendering costs of JavaScript more evenly.
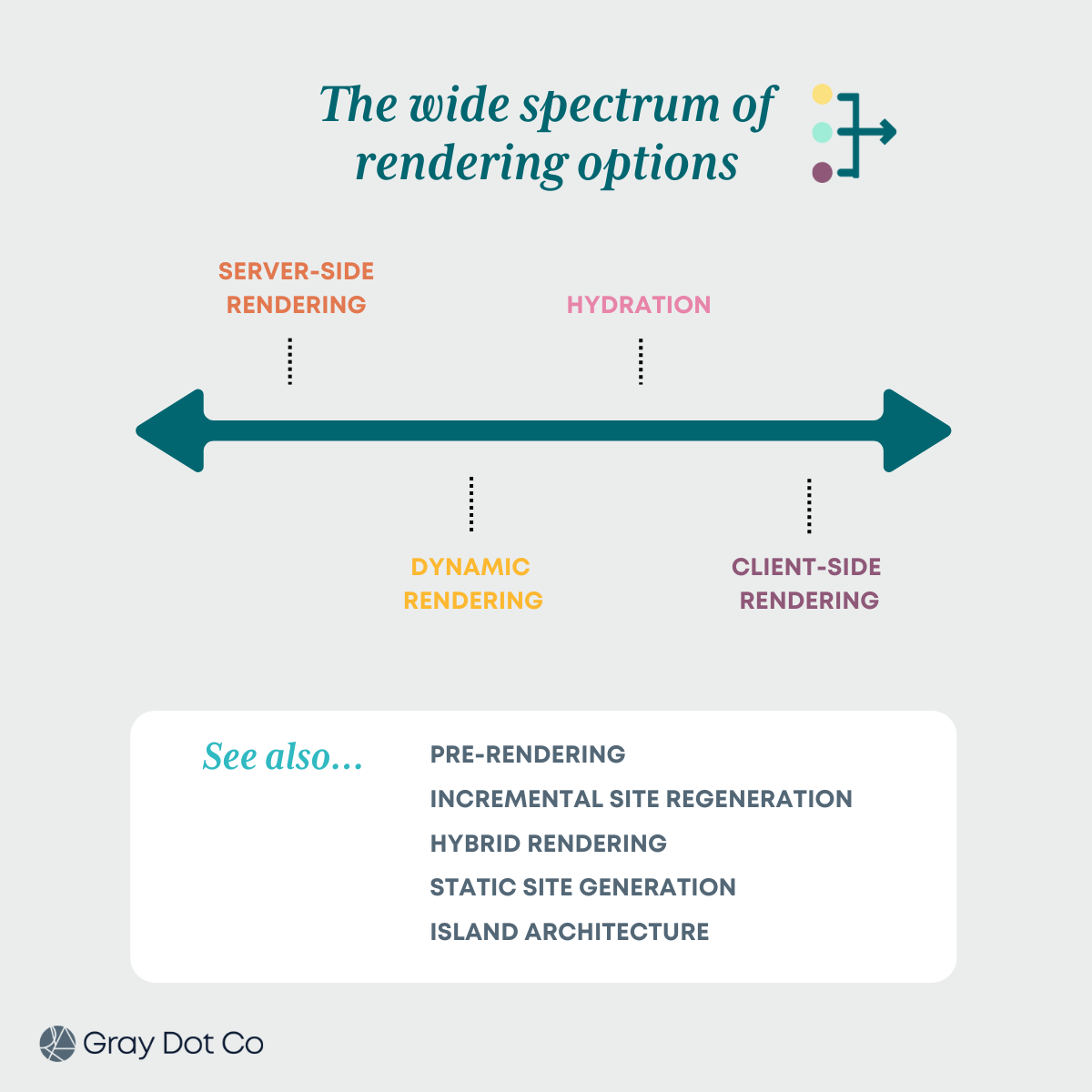
We won’t get into the finer print of how JavaScript rendering affects indexing here, because for the purposes of this article, the above explanation will do.
If you want to learn more about rendering in all its glory, you can go into greater detail with Google.
Remember: Rendering isn’t a right!
Search engines don’t have unlimited resources. Google’s Web Rendering Service will save valuable resources without signs that the juice will be “worth the squeeze.”
That means a URL might not make it through the rendering queue as frequently if the site hasn’t established signals that the page is valuable to users, like page copy, internal links, and backlinks.
When a URL doesn’t go through the rendering queue - and no important page content is available without it - then search engines don’t have context to evaluate the page. Therefore, it’s unlikely to be indexed and/or ranked effectively.
Keep that in the back of your mind as we move on to resolving common JavaScript issues!
A Chrome Extension for JavaScript audits
We built the Rendering Difference Engine to identify SEO signals added, removed, or altered during JavaScript rendering - in just one click - without digging into the code.
Identifying JavaScript issues starts with the symptoms
Taking note of the symptoms is the first step of narrowing down which JavaScript issues are most likely ailing the site.
So, what are you seeing?
You don’t need to be a developer to render a diagnosis.
Symptom: Some or all pages aren’t on Google.
There are pages you want indexed, but they’re not (according to Search Console) nor do they appear in SERPs.
Check for these JavaScript issues.
- Google can’t discover the URLs.
- JavaScript is changing critical indexing signals.
- Contextual <head> elements are missing or misplaced, so search engines won’t understand the page or its content without additional rendering costs.
Symptom: Our site or pages on our site aren’t performing well.
Key pages are experiencing performance struggles, or the site seems to be lagging across the board.
Check for these JavaScript issues
- Google can’t access some or all of the page content.
- Some or all links aren’t valid, so link equity is diminished.
- The site is dependent on JavaScript rendering, and likely making Google work harder than it wants to.
- There are meaningful differences between the response and rendered HTML.
- Critical JS errors keep some HTML from rendering.
- Any of the indexing issues noted above can also impact performance.
Symptom: URLs that shouldn’t be indexed are in search results.
Google Search Console indicates that junk pages are indexed such as URLs that canonicalize to other URLs, or empty/error pages.
Check for these JavaScript issues
- Google doesn’t know whether the page should be indexed, because important signals are missing, misplaced, or contradictory.
- Google is finding URLs due to dynamic generation of unwanted pages.
- 404s aren’t functioning properly, which is leading to potential index bloat.
Symptom: I’m having trouble crawling my site.
When running a manual crawl with a third-party crawler:
- Some or all URLs are missing from the results.
- Important tags or other page info do not appear in the crawl results.
Check for these JavaScript issues.
- The site does not have valid URL variations, or they aren’t crawlable.
- The site doesn’t have an XML sitemap.
- Some or all links aren’t valid
Symptom: Images aren’t in Search Results or aren’t performing well.
Some or all image URLs aren’t indexed according to Search Console — or, indexed images rank poorly.
Check for these JavaScript issues.
Symptom: Search Console is reporting lots of soft 404s.
There are pages on the site that appear to be invalid or non-functioning pages, but they load without serving a 404 status code.
Check for these JavaScript issues.
Symptom: Performance is suffering following a migration.
The site was redesigned or moved to a different frontend framework.
Check for these JavaScript issues.
It’s time to run a full JavaScript SEO audit, because migrations can result in many meaningful changes.
Symptom: Pages aren’t loading in the browser.
You’re seeing a blank page in your browser when visiting a valid URL.
Check for these JavaScript issues.
- The site is dependent on JavaScript rendering, and JavaScript is turned off.
Connecting symptoms common JS SEO issues
Resolving performance and indexing problems on the site come down to implementing JavaScript SEO best practices based on the issues at hand. So let’s dive into the issues themselves, how to validate the common cause(s)of each, and what an optimized end-state looks like.
Issue: Google can’t discover URLs.
Crawlers follow links to find new pages. If for some reason a crawler can’t follow links on your site, it can’t make its way to pages it doesn’t know about.
In the absence of internal links, URL discovery is dependent on an up-to-date sitemap or backlinks Google finds when it crawls other sites. Unfortunately, backlinks are often out of our control.
The following causes illustrate common reasons this issue pops up.
Cause: Unique URLs don’t exist or aren’t valid.
If the URL doesn’t change in the browser, or page-routing uses a # in the URL, then it’s not individually indexable. Search engines won’t be able to deliver users to the right “place” on your site, nor inherently understand the context of the page.
To solve this issue, identify & implement the URL routing plugin that’s specific to your JavaScript stack - for example, Vue Router or ReactRouter.
# (hash) URLs are technically known as fragment URLs. Historically, they were created and used to link to content within the same page, such as a lower-page heading. You’ve probably heard them referred to as “jump” links or internal anchors.
However, JS platforms sometimes use hashes to load different content than what’s on the page. #! (hash-bang) URLs were created as an early attempt to accomplish that.
In both cases it’s a valid URL variation for users, yet it doesn’t work for Google.
Instead of using hash URLs, Google recommends using the History API. Our general advice is that URL routing should use directories, slugs, and parameters as needed to serve distinct URLs.
Cause: Anchor links aren’t coded properly.
Href tags and anchors are the most common internal link structure you’ll see in HTML. That’s because Googlebot - and most search engine crawlers - don’t accept other link formats like router, span, or onClick. Google can only discover your links if they are <a> HTML elements with an href attribute.

Because these other methods are all valid links from a dev and end-user standpoint, it’s up to an SEO to communicate the context that they won’t work for Google — and make it a part of cross-functional documentation. If you need help, refer to Google’s existing documentation around crawlable linking.
Cause: Pagination isn’t set up properly
Pagination is a common issue for SEO as a whole. It’s often implemented via an out-of-the-box JavaScript plugin or library. The three most common variations are:
- “Load more”
- Infinite scroll
- Parameterized pagination (e.g. “?page=3”)
The challenge is that the default functionality of these plugins rarely follow Google’s pagination best practices.
Typically, URLs linked on the “next page” will load in the browser for the user, but the URL will stay the same. Or, unique pagination URLs exist, but have other common issues:
- They aren’t linked within an <a href> in the HTML.
- Variants aren’t indexable due to meta robots or canonical settings.
This causes two major problems:
- If Googlebot can’t access pagination variations, it won’t be able to discover any items linked on page 2+.
- If Google can access them, but they aren’t indexable as unique & valid pages, then items linked on page 2+ won’t receive internal link equity.
In such cases, all items (blogs, products, etc.) linked on “deep” pagination variations are unlikely to be found and/or perform well in search.
To resolve this, pagination should:
- Have unique URLs for variants (page 2, 3, etc.)
- Follow proper linking protocols (e.g. an <a href>)
- Be crawlable and indexable (don’t block with robots or canonicalize to page 1)
Here’s how Google recommends setting up your pagination and best practices for infinite scroll.
Cause: No or incomplete XML sitemap.
Outside of links, the XML sitemap is another tool at your disposal to help search engines discover pages. All major JavaScript frontends have built-in functionality or available plug-ins that will create a sitemap and keep it dynamically updated with valid URLs.
Once a sitemap is created, you can run it through your favorite crawling tool to check for any unwanted URLs.
Make sure that the correct sitemap is submitted to GSC and noted in the robots.txt, so Google is able to reference the URLs in crawls.
Issue: Google can’t crawl some elements of the page.
Rendering isn’t all or nothing. It’s common to see setups where Google is rendering pages, but some JavaScript-served content is still unavailable. That means elements like copy, images, and links are potentially missing from the crawl.
Most JavaScript tools are helpful in looking for discrepancies between response and rendered HTML. They can give you information like word- and internal-link counts, but they don’t tell you what’s missing, per se.
That’s why it’s beneficial to roll up our sleeves and do a manual spot check. It’s a step that everyone should probably include in their JavaScript SEO audit.
Choose one URL from every major page template on the site (homepage, service/product, collection, blog, etc.). Run that page through the Test Live URL tool in Search Console, and use the search function to locate important images, links, copy, and media in the rendered HTML.
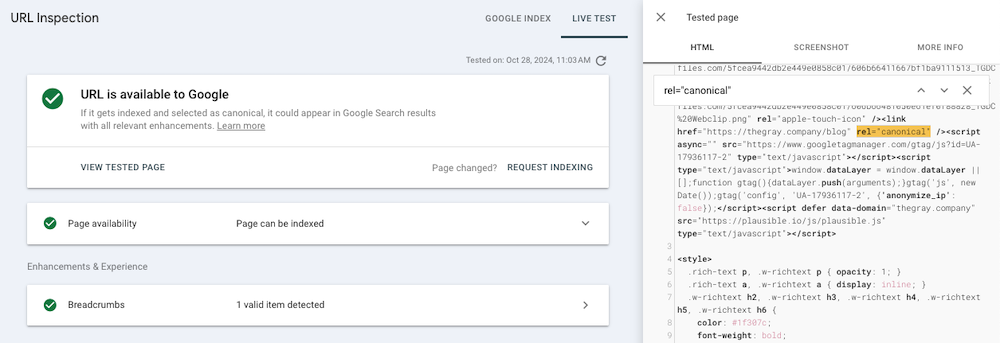
If you find elements that are missing:
- Identify which page elements are to blame.
- Common culprits include tabs and accordions, links in pagination, or links in a drop-down navigation module.
- These elements are often implemented in the same way across the site and therefore may need to be fixed in more than one place.
- Consider how critical the missing context is to the page in question - and even how critical that page is to your site.
- Then work with your development team, as needed, to make it available.
Issue: Content loads dynamically after a user interaction.
Remember, crawlers can’t click, scroll, hover, etc. So if links or copy aren’t in the HTML until a user interaction takes place, then they are unavailable to crawlers.
For example, accordion dropdowns are often a UI element in organizing product-page information. However, a crawler can’t click to expand the accordion.
If you see the “hidden” content in the HTML (you can use Chrome Inspect) before you click to expand it, then your accordion content is not using JavaScript to populate the content. That’s good news!
If that content isn’t appearing in the HTML until after you click, it’s unavailable to crawlers.
Issue: The site is dependent on rendering.
If your site is dependent on client-side rendering (or CSR-leaning) to serve content, then there is little to no “meaningful” response HTML. This isn’t inherently a problem, but it’s worth noting that sites with content available prior to rendering generally see a 25-35% traffic lift.
First dig in and understand whether:
- Search engines can access all the important page content once rendering is complete.
- Critical <head> elements are available prior to rendering - as recommended by Google - to ensure critical page context & indexing signals are present in the response HTML.
Critical
- Title
- Meta description
- Meta robots
- Canonical URL
Important
- Navigation links
- Pagination links
- H1s & other headings
Ideal
- On-page copy
- In-content <a href>s
- Images & alt text
If your pages include critical signals only (e.g. not important or ideal signals), but still aren’t getting indexed and/or ranking well, it’s likely that rendering is causing performance issues.
There are a few ways you could go about checking, but the quickest and easiest might be using the Rendering Difference Engine. Our team created this handy Chrome extension to identify SEO signals added, removed, or altered during JavaScript rendering - in one click - without digging into the code.
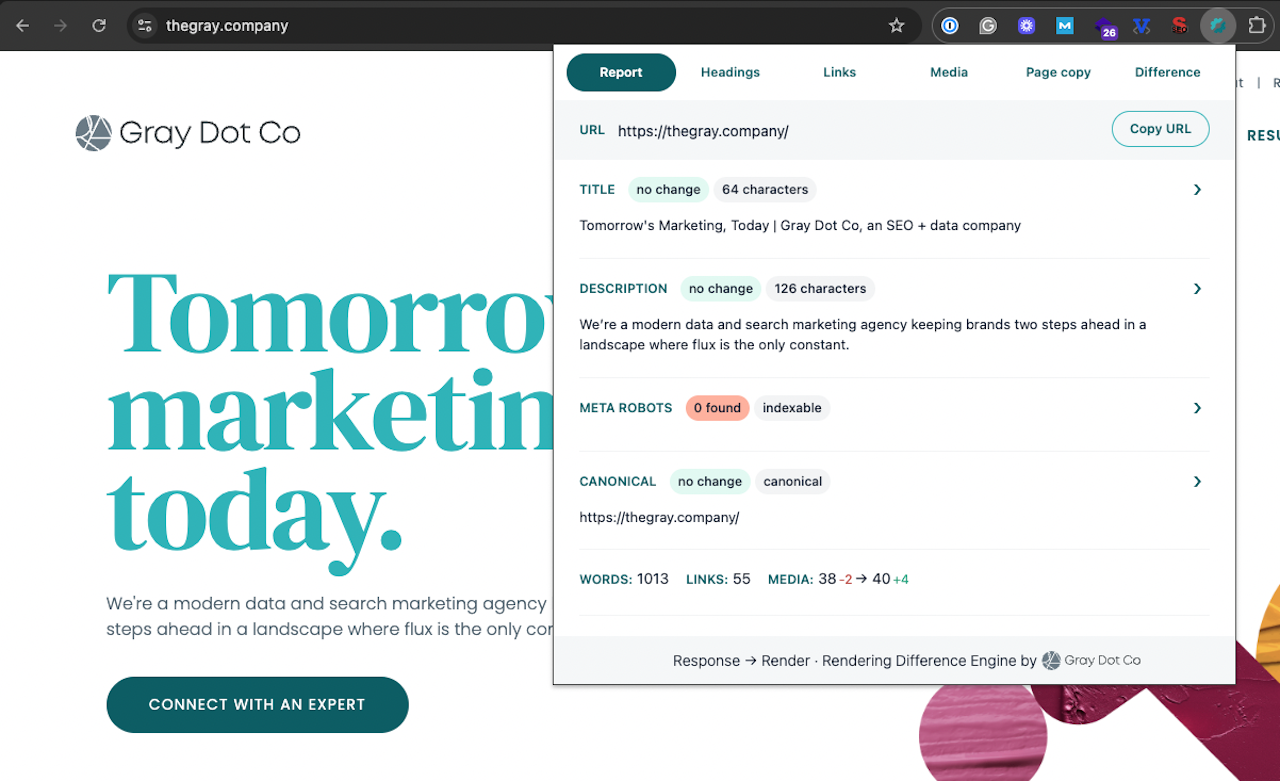
If the URL has little to no important page context in the response HTML column, you’re likely not serving it.
Cause: The frontend is set to out-of-the box configurations.
Regardless of which JavaScript framework is building the site, it likely defaults to client-side rendering or hydration (which is similar) at implementation.
Why do they default to CSR if it can cause SEO issues? Well, it has performance benefits. CSR allows devs to make sites that are more interactive (page transitions, animations, etc.), while putting the cost of running those sites on the user and their browser.
It generally takes some lifting on the dev side of things to make sure:
- Search engines are able to discover and crawl distinct, valid URLs on the site.
- Key authority signals, like internal links, are crawlable.
- Content that we as marketers define as “critical” or “ideal” to the page are accessible to search engine crawlers.
That’s a big part of why it’s so important to be able to explain the issues and their impact to developers. They’re approaching rendering from a completely different perspective.
Plus, these changes for the dev team often relate to the configuration. The earlier you communicate these needs, the less “heavy” the change is.
Cause: Not enough authority signals.
The best way to improve the chances of the Web Rendering Service moving a URL through the queue is to show that the URL is important.
We can do that through the same elements that help URLs rank well: an authoritative domain, self-referencing canonicals, metadata that shows relevance, links from other important pages on and off the site (learn more).
Issue: Crawlers can’t access page-building resources.
In order to render a page, Google needs to be able to discover and unpack critical building blocks such as media and scripts. When there are issues that prevent this from happening, it’s not possible to render the page completely and accurately.
Cause: A critical directory is blocked by robots.txt.
Script (CSS, JS) and image files often nest in a dedicated subdomain or subfolder. It’s not uncommon for these types of directories to end up in a robots.txt disallow. Which means lots of resources are unavailable to crawlers. Yikes!
Meanwhile, in the client browser, you won’t notice a thing.
It’s pretty easy to skip the tools and spot-check the robots.txt if you know which directories the files live in. (If not, the dev team definitely will!)
Cause: Critical JS errors are causing parsing issues.
When using JavaScript on a page, it’s common to see errors logged in Chrome Console. That’s true whether it’s on a fully JS-supported platform or just loading some interactive elements on the page.
Many of these errors - dare we say even most of them - do not cause problems for users and search engines. In fact, it’s pretty accepted in the dev community that many of these JavaScript-related errors can be ignored.
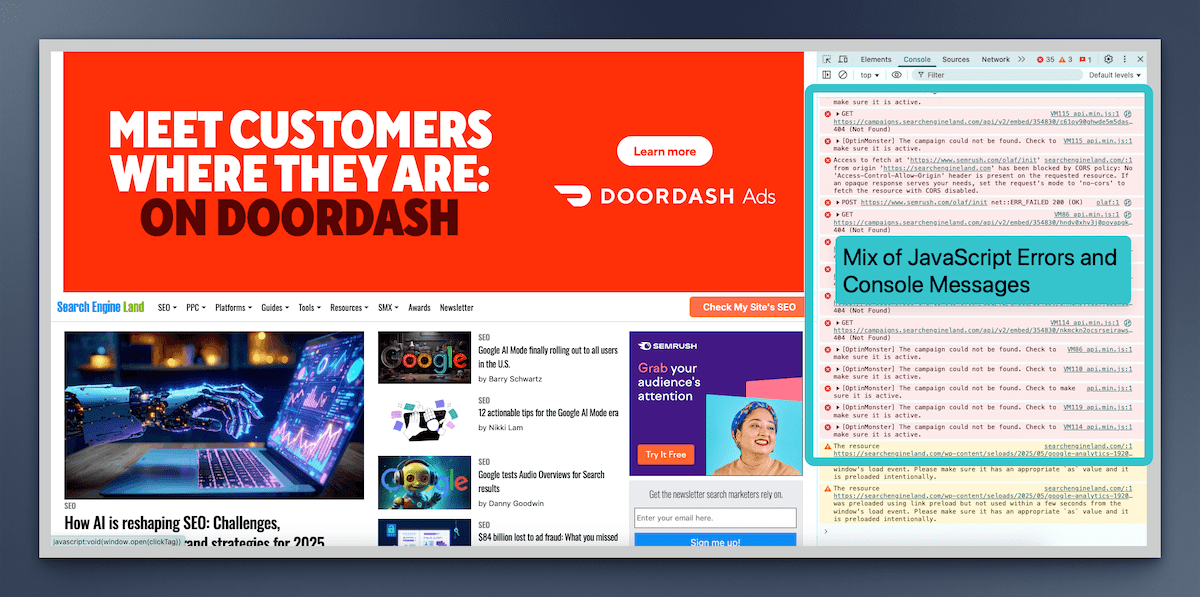
However, some errors will make a page unparsable. The rendering service can’t separate the individual HTML elements, structure SEO content in JavaScript, or identify relationships. In which case, you’ll usually see some sort of visual impact on the live page too.
In the Test Live URL tool, you can check for errors under JavaScript Console Messages in the More Info tab of the View Tested Page report. With that being said, the best way to understand if errors are causing the problem is to talk to a dev.
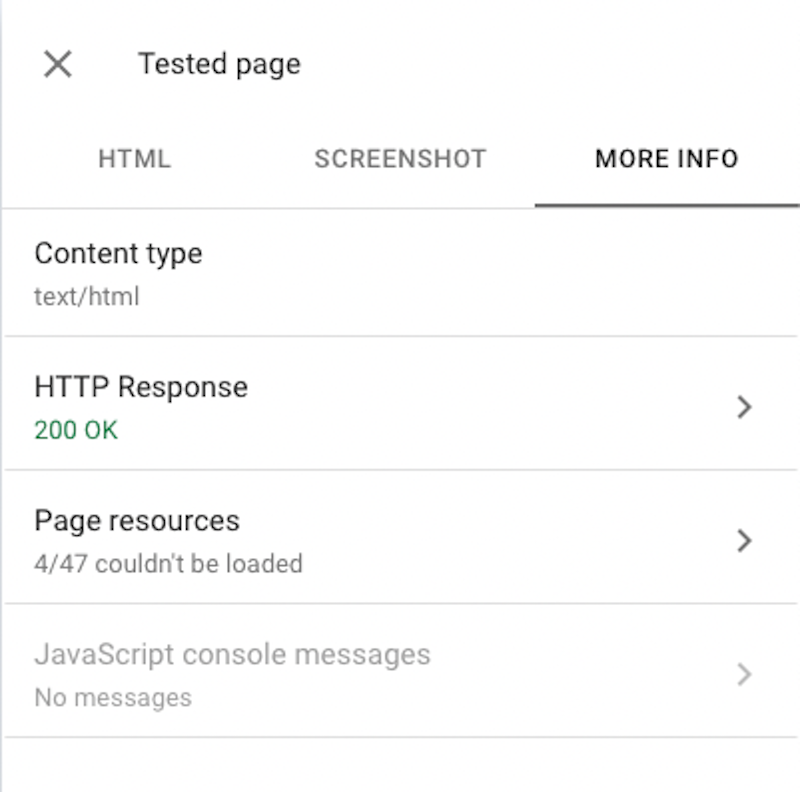
Don’t preface with, “look at all these errors, they’re hurting our SEO.” (Not that you would!) Explain the issue you’re seeing with rendering, give context as to why it’s important, and ask the experts if there’s a connection.
Cause: Images are configured improperly.
Similar to links, images have to be properly configured and coded to be SEO-friendly. First check if Google is able to crawl the directory where images are stored.
If that access looks good, it’s likely that images are called in the CSS instead of the HTML. To be indexable, images must use an <img src> tag.
Note: Not all images are important for indexing. For example, decorative images implemented in the CSS are fine as-is.

Issue: There are meaningful differences between response and rendered HTML.
JavaScript can add, remove, move, or alter content after a page is rendered (or built in a client browser). That includes all-important elements like:
- Meta robots tag
- Canonical URL
- Titles
- Meta descriptions
- Page copy
- Media, like images and video
- Internal & external links in the page body
- Navigation elements
At the page level, that means important directives, signals, or context could be incorrect. At scale, many discrepancies between response and rendered HTML makes search engines work harder than they want to. And we know that’s never great for SEO.
As far as JavaScript SEO tools go, crawlers are your best friends. They make checking for differences between the two sets of HTML a lot easier, thanks to their rendering capabilities.
Sitebulb is a favorite for spotting any discrepancies. If you’re crawling a JavaScript website with Sitebulb, the Render vs. Response report calls out any differences for you.
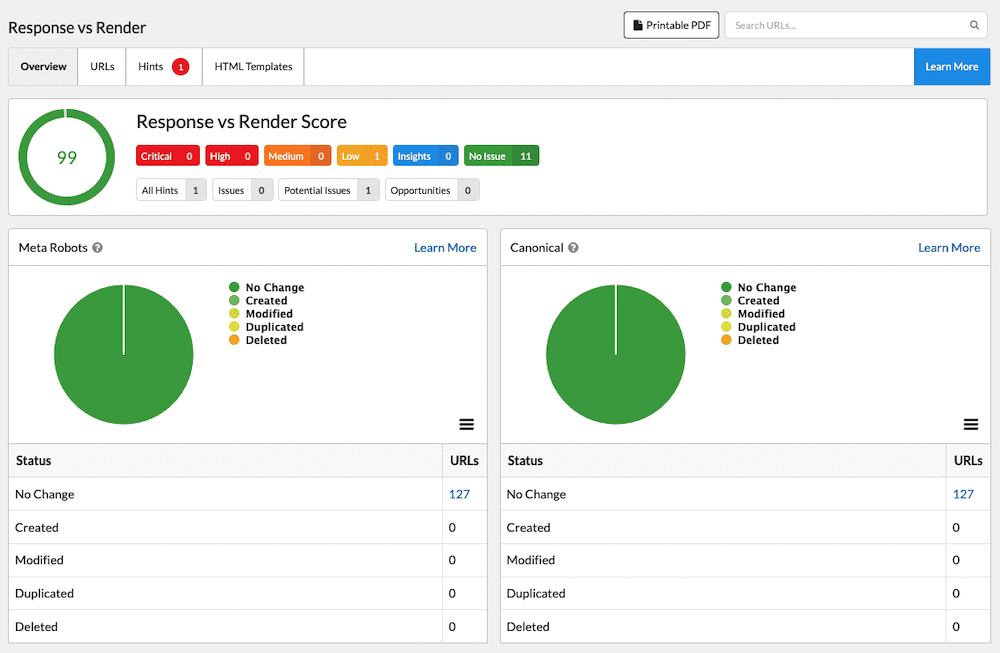
Or in Screaming Frog, you’ll want to run a crawl with JavaScript rendering enabled.
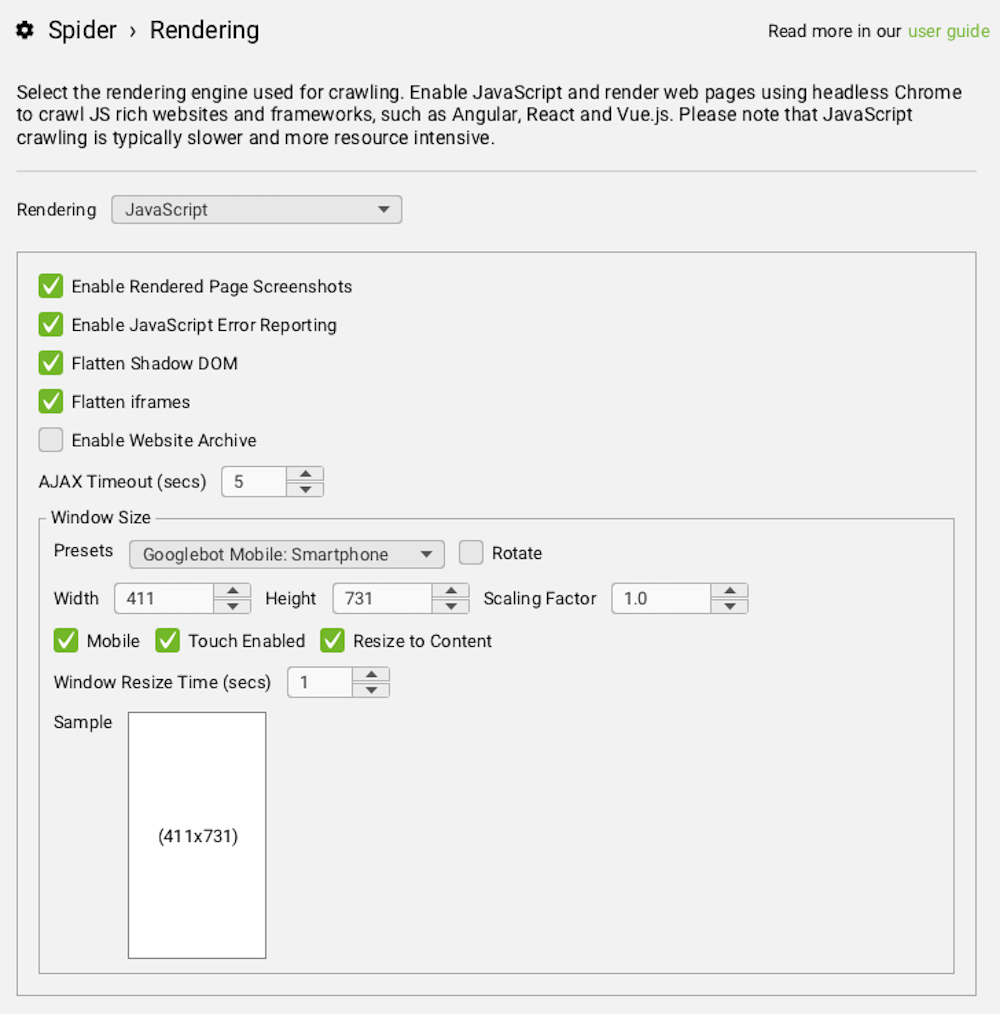
In either case, you can connect the tool to Google’s URL Inspection API to get info like the date of the last page crawl, Google-selected vs user-selected canonical, and index status.
Cause: JavaScript is changing indexing signals.
Critical signals - which we identified earlier - are more important than others to include in the response HTML. Meta robots and canonical tags are two of the most important, because they suggest whether the page should be indexed at all.
It’s not uncommon to see instances where the signals served in JavaScript are different from those in the response HTML. This can cause confusion and indexing problems, because there is conflicting information.
Issue: Critical <head> elements are missing or misplaced.
The <head> is where indexing-critical tags are served in HTML, including metadata, meta robots, and canonical URL.
A crawler is always going to look at the <head> first to understand whether it should crawl and index the page. Instructions that aren’t in the head may or may not be found or utilized correctly.
Cause: Indexing directives are served in JavaScript.
If Googlebot finds a meta robots tag in the response <head> - where the correct tag should go - it may take that directive and run with it. If that tag is set to noindex, it often won’t bother to put the page through the rendering queue. If meta robots is then set to index upon rendering, Google may never see it.
That said, when pre- and post-rendered HTML have conflicting canonical and indexing signals, it’s not always as simple as “Google will follow the initial instructions.” All bets are off, and anything can happen!
Meta robots and canonical tags should be accurately set in the response HTML and remain unchanged in the rendered HTML, for predictable & accurate results.
Cause: There is no metadata.
JS frameworks often use plug-ins or other libraries to create the <head> element of a page and incorporate metadata. If you find that your site is missing the metadata that you expect to see, then here’s a method to identify potential solutions and pass that information to your developers:
- Identify which platform or JS framework your site is using. We recommend using a browser extension called Wappalyzer to help with this identification. If you’re unable to tell, you’ll need to ask your development team.
- Research the available tools for metadata handling for your particular platform (e.g. React often uses a library called Helmet).
- Once selected, create documentation on how you want those meta tags to appear, so the dev team can properly configure that. (This is a great time to consider global fallbacks vs custom fields required in the CMS!)

Issue: JavaScript is generating unwanted pages.
One of the most powerful reasons that sites use JavaScript is the ability to dynamically create pages. That can come in especially handy for elements like paginated results or filtered results pages. But without the right constraints, those dynamic capabilities can cause problems.
Cause: Google is crawling build URLs.
Some front-end frameworks use static site generation (SSG) as a rendering solution. A static site generator takes raw data and a set of templates, and uses them to create static HTML pages for URLs on the site.
What does this mean? Typically, most or all content is in the response HTML without the costs of server-side rendering. (It’s a great solution, but note that it won’t work for pages that require high interactivity.)
While it’s going through this “build” process, an SSG creates a new folder on the site server each and every time the build is run (often daily or weekly). The pages are built at URLs that nest in this folder (/build is common).
Once the build is finished, that content is moved over to the public HTML file (aka your website). But if and when a build is interrupted, that porting process doesn’t happen.
The result is a “build folder” with junk, duplicate pages - often a significant volume of them - that are accessible to search engines.
When using a static site generator, it’s a good idea to clean up build folders routinely. Consider asking devs to set up a cron job (e.g. an automated task that runs on a specified schedule) that cleans them up every day, which should be relatively easy to implement.
P.S. if you’re not seeing any signs of build URLs showing up in Google Search Console, consider disallowing the build folder to your robots.txt. (But not if Google has already found some of these URLs, because a fun nuance of crawling and indexing is they’ll remain in the index)
Cause: Pagination URLs are not constrained.
A common problem of pagination is URL variants that don’t end. For example, a site might link to page 34, even if there are only 10 pages of results.
When search engines find these types of URLs, they often report as soft 404s because they do not serve a 404 status and they don’t serve any content.
This is typically the result of malformed pagination linking: the final page(s) in the series linking to subsequent pages without “checking” to see if more pages are needed.
The simple solution is to build in pagination logic to stop adding links when there aren’t more results.
Cause: Pages don’t serve a true 404 status code.
This is another problem that you’ll often see if a site uses the out-of-the-box configuration for an SPA (Single-Page Application).
By default, every single page will return a "200 Success" HTTP status code - whether that’s accurate or not.
It’s important that you can share the ideal end-state with developers so they can make the proper adjustments to properly serve a 404 status code on an SPA.
Alternatively, we see many sites where invalid pages redirect to a dedicated 404 page, which also doesn’t serve a 404 status code. In which case, there’s a good chance that the 404 URL ends up in Google search results too. (All those redirects are passing equity to the 404 URL!)
Remember, it’s not always a JavaScript error.
In SEO, the phrase “it depends” comes up quite a bit — because it’s layered, nuanced, and not always easy to diagnose. Many culprits can individually or collectively combine to create indexing and performance issues for today’s brands, from site authority to content quality and tech SEO.
Plus, JavaScript isn’t new. Google, SEOs, and devs have continued to evolve and enhance the way they approach JS sites. Today, there are plenty of JavaScript-powered sites that perform well in organic search.
When the site is experiencing performance issues, accurately understanding the full story can feel complex and convoluted. That’s why we as SEOs need to take a step back sometimes and conduct a more multi-faceted investigation that illuminates why organic traffic is down.
So keep in mind as you dig in - the issue you are seeking might not be about JavaScript - or even about technical SEO!
Communicate the issues clearly to keep things moving.
Finding the issues is part one of optimizing JavaScript SEO. The next is getting the business - and especially the Product & Engineering teams - bought into the value of and need for the work.
Now that you have a solid understanding of the rendering process and common JavaScript SEO issues, it’s a matter of speaking the same language. That comes down to how you document the issue.
The best way to get everyone looking at the problem from the same perspective is to create a well-articulated SEO business case.
Our team’s here to help — whether it’s tracking down the issues, translating them into the right documentation, or helping communicate and connect the dots.
