
Editor’s Note: AI search experiences are evolving rapidly. The way bots crawl content and how LLMs use that data will undoubtedly change over time. We’ll strive to update this article when there are major changes to report!
Since this piece is a strategic overview of a highly technical topic, there are some generalizations to help less technical audiences understand how things work.
The technical setup of a website plays a big role in SEO performance. But how does tech factor in when it comes to generative engines?
The content you serve on your site is a big piece of growing visibility within LLMs. How that content is served from a technical perspective is equally crucial. Maybe even moreso, because it determines whether generative engines can access your content in the first place.
Much like tech SEO, an AI-friendly tech configuration is largely a matter of what bots can crawl onsite. But there are some key differences in how search engine bots and AI bots crawl the web, the actions they can take, and the types of content they choose to gather for a dataset.
So let’s take some time to cover the essentials of crawling from an AI perspective, including what’s crawlable, how it’s crawled, and why it matters for AI search visibility.
What data does AI search use to generate answers?
Generative engines rely on three distinct sets of data for context and training.
- Pre-ingested and pre-processed “training materials” which often include books, media/news outlets, scientific journals, wiki-data sources, UGC like Reddit and Youtube, and prioritized webpages from “quality” sites.
- This is the default data source that LLMs prefer because it’s less resource intensive than retrieving data from other sources. In other words, it’s cheaper.
- The live web by using an MCP (Model Context Protocol) or RAG (Retrieval Augmented Generation) to “search” sources via an API.
- These different tools accomplish the same goal in that they allow generative engines to interact with external data when answering a prompt. (Note: Both are able to query Google!)
- Live feedback where humans respond to LLM answers in real time, creating a “feedback loop” aimed at improving results - and potentially, related searches - for other users.
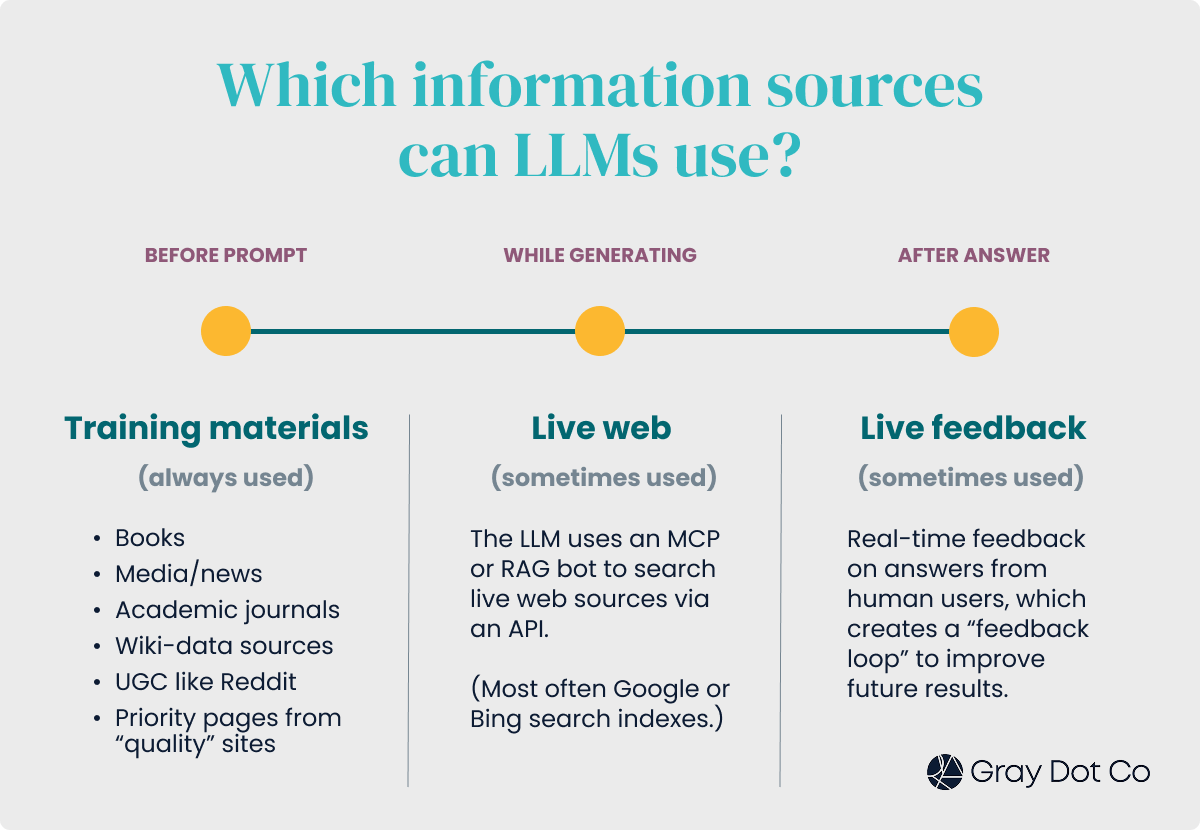
Crawling comes into play with the first two: training and live-web materials are gathered from sites, though at very different times!
For example, ChatGPT has distinct bots with distinct functions:
- GPTBot crawls the web to extract data for use in future training material updates.
- ChatGPT-User extracts specific data on demand on behalf of a user. It’s also the bot used for CustomGPTs.
- OAI-SearchBot is a specialized bot that crawls the web to discover and index relevant sources for ChatGPT search features.
The bigger your site, the higher the chances that you'll see each of these user-agent variations in your log files.
How does AI search gather data from sites?
The first important distinction is that the user-facing technology itself (i.e. the LLM tech) doesn’t crawl the web for data.
In order to gather training materials and information from the live web, AI-powered search tools rely on bots. We call them “AI bots” as opposed to “LLM bots,” because they’re bots from AI companies.
That probably feels familiar if you’re an SEO, because Google search uses a bot, Googlebot, to crawl the content of a website and gather data for the index.
How does AI crawling differ from search engine crawling?
While the 50,000 foot view might feel similar, there are a few key differences to note between how AI bots and search engine bots crawl.
- Indexing - Search engine bots crawl the web to create a searchable index, whereas bots from LLM companies are more analogous to scraping technology. (i.e. They grab specific text & data if and when they need it.)
- The exception is OAI-SearchBot which indexes sources to support citations in OpenAI’s SearchGPT prototype.
- Rendering - Google has a process that allows it to render JavaScript and retrieve rendered HTML, whereas AI companies generally don’t.
- Content - The content that search engine bots and AI bots choose to crawl differs, which we’ll get into a bit later in this article.
View content like an AI bot.
Our house-built Chrome extension lets you audit any URL and see the page data available to generative engines in a quick, one-click report.
AI bots and JavaScript rendering
Much of the differentiation between crawling in SEO and how AI search gathers data boils down to JavaScript.
Google’s crawling process includes a web rendering service called Filament. It can render HTML nested in JavaScript files and return what’s known as “rendered HTML.” Googlebot can then crawl the rendered HTML to find content that was previously unavailable in the HTML from the server response (response HTML).
AI bots generally cannot render JavaScript or crawl rendered HTML. (Although that will probably change over time!) That’s important because a large majority of modern websites are built using JavaScript frameworks and libraries.
As a result, many websites don’t include some or all of the critical page content in the response HTML. They serve content like copy and links in the rendered HTML, but AI bots can only crawl the response HTML.
Some Caveats
- Gemini - As Google’s AI assistant, Gemini gets the luxury of tapping into any rendered HTML already collected as part of the existing process for Google Search.
- Claude - At Tech SEO Connect 2025, Giacomo Zecchini’s presentation on the implications of rendering, style, and layout referenced data showing that ClaudeBot renders JavaScript in some cases.
- ClaudeBot is the AI bot used by Claude to gather content for training materials.
- Giacomo did not include Claude-User (live web crawler) or Claude-SearchBot (indexing) in the list of crawlers that render JavaScript.
- URLs indexed on Google - If a page’s rendered content is available to Google, and an AI bot or scraper can directly “Google” it, it’s conceivable that the content is accessible to LLMs like ChatGPT.
- We don’t recommend relying on this possibility versus making important content directly crawlable on the site. Results may vary!
Plan for change
One thing is for sure: as generative engines evolve and become more sophisticated, so too will the way they collect, retrieve, and use information.
We should expect changes to crawling AND how LLMs use any data collected. Even in the near future, it’s likely more AI-powered search experiences will incorporate rendering processes.
Why? Because just like Google, generative engines are constantly working to improve the quality of answers and the overall user experience.
Which content can AI bots crawl on a site?
Let's start with the obvious: you can set crawl instructions for AI bots via your robots.txt file, much like you can for search bots. Though - word of caution - not all LLMs play "nice", and they may not follow those rules. Malicious and "information greedy" web crawlers exist.
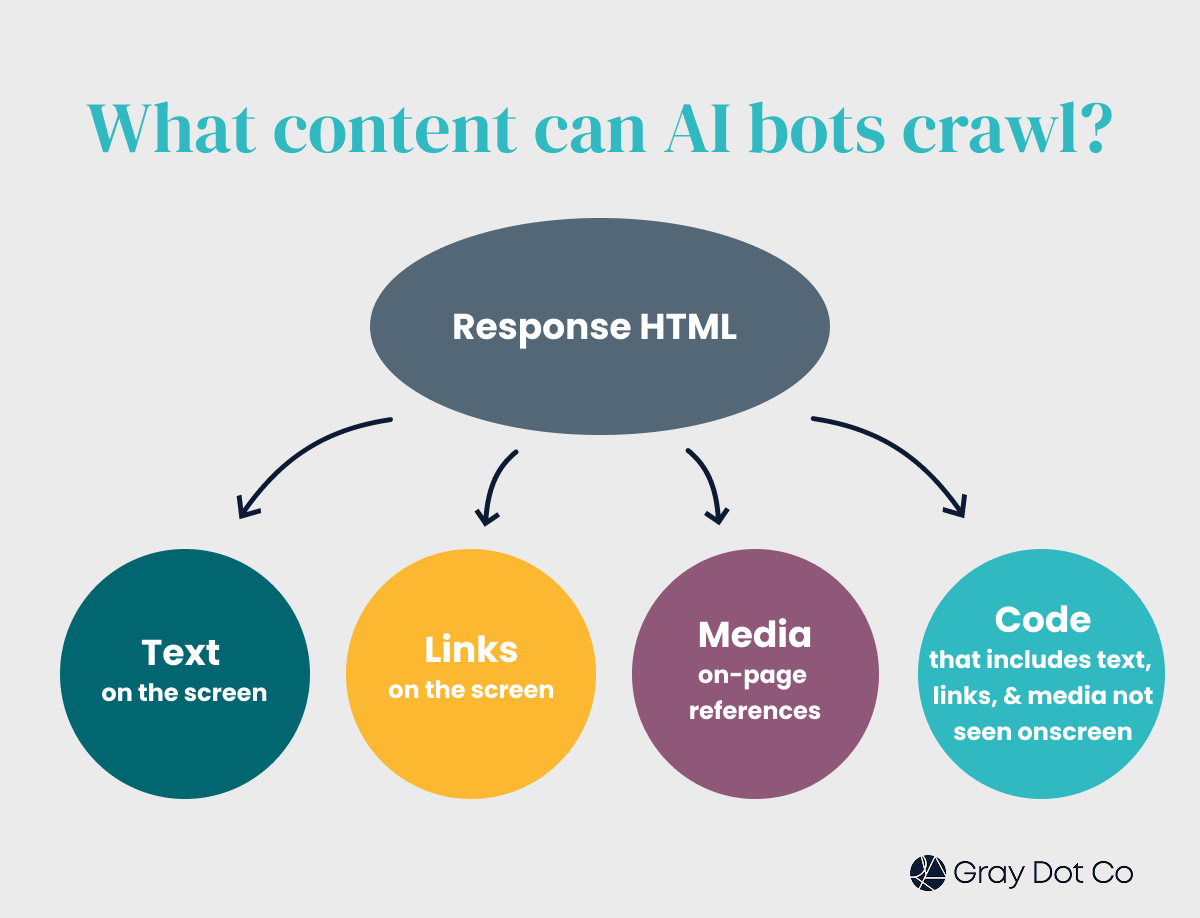
But for the most part: AI bots can generally only crawl response HTML, for those pages they have access to.
Response HTML is the HTML that comes from the server response, and it’s available to bots and browsers without the need for JavaScript rendering.
AI bots can gather the following types of content when crawling response HTML:
- Text that users can see like headings and on-page copy
- Links that users can interact with, such as links to product pages
- Media like logos, images, videos, and audio
- Text, links, and media in code that is not inherently visible on the page, including metadata, open graph, JSON snippets (like structured data), and code comments
This is what’s available to collect.
However, it doesn’t necessarily mean that all of this content is used when AI generates answers to relevant prompts.
Which crawlable content do generative engines use?
We know what’s visible and available to AI crawlers. How, when, and how often generative engines actually use the data is a bit of a black box. It’s different from one LLM to the next, since each builds its own pipeline and process for generating prompt answers.
Content types that LLMs definitely use
- Text - text that’s in the response HTML is a primary input in training materials for large language models (hence, language).
Content types that LLMs can (but may not) use
If and when LLMs use this data, it is likely converted to text and treated as such.
- Links - Generative engines use links for citations, as well as to discover new pages when crawling a site.
- Media - LLMs care more about text than media by nature, but use media when it’s deemed helpful for response generation.
- Code snippets - How and when code snippets are used in AI search is a contentious topic, but we know that AI bots can see them, and thus, may use them.

All of this has implications when it comes to technical fine-tuning for LLM visibility. That goes for sites that want to boost their visibility and sites that want to stay out of answers.
What it means for generative engine optimization
Knowing what AI bots can and can’t crawl supports GEO efforts in a couple of ways:
- Making sure AI bots can access the content you want to feed into generative answers about your brand and relevant topics
- Identifying any information AI bots can crawl that should NOT feed into generative answers, because it could be problematic for your brand
Making important context available to AI search
One of our favorite ways to think about LLMs is that they’re essentially “word calculators.” They generate answers by calculating the probability of the best next word, based on how frequently words appear in certain contexts within their data sources.
When content is only served in rendered HTML, it’s generally unavailable to AI crawlers. That means it won’t get crawled and collected as part of the dataset, and it won’t be used in the word-probability calculation.
That’s pretty important if information about your brand, products, expertise, value propositions, etc. are missing from the response HTML.
Sure, there may be information on external sites about your brand, and LLMs likely use this information. But content on a brand’s own site is an opportunity to enrich and control the narrative.
When critical context is invisible to AI bots, it potentially hurts a domain’s chances of ranking in generative engine answers. Plus, it hinders the generative engine’s ability to truly understand your brand entity, where it may be relevant, and the accuracy and comprehensiveness of answers.
For example…
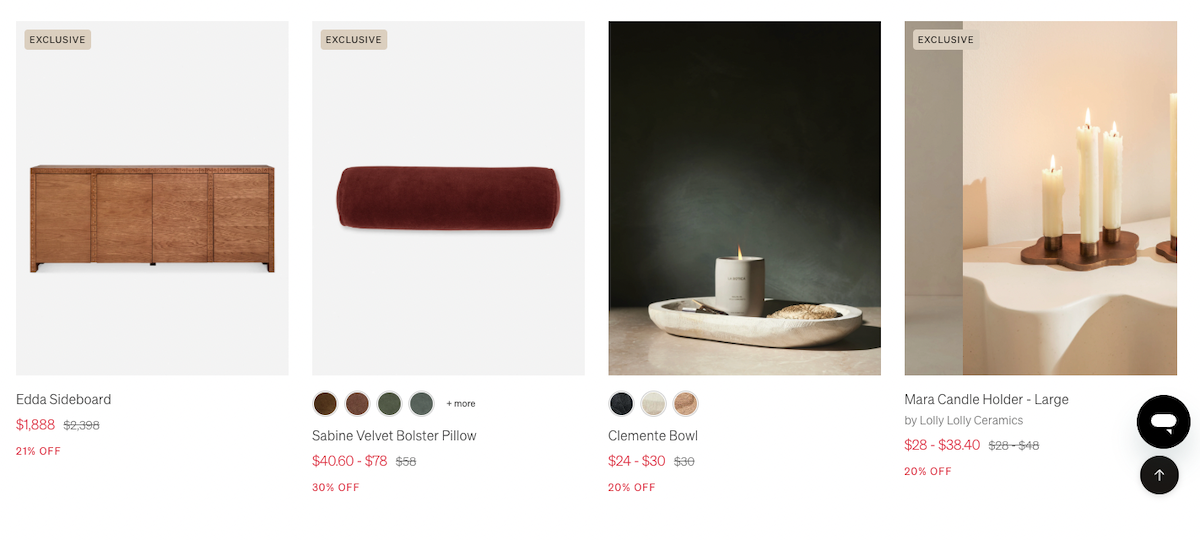
Take this well-known eCommerce website where product names on a collections page are unavailable in the response HTML.
Clearly, this cute “Mara Candle Holder” is visible to users who visit the page.
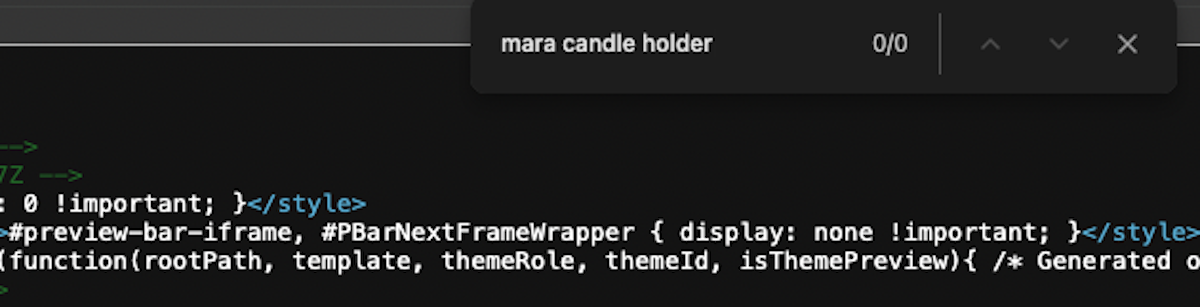
But when we right-click and “view source” to see the response HTML, a search for “Mara Candle Holder” yields zero results.
Whereas when we right click and hit inspect to view the rendered HTML, Mara Candle Holder is available as an <h3> heading. (We’ll talk about some easier ways to compare the two sets of HTML when we get into auditing your site for AI crawling.)

That goes for any product links on the page as well. The links are unavailable to AI bots as a part of the crawling process, because they’re only served in the rendered HTML.
That’s just as important because missing links prohibit AI bots from effectively discovering and crawling new pages, which in turn prevents content from becoming part of the training dataset retrieved for generative engines.
Keeping problematic content out of AI search
On the flip side, the ability of AI bots to collect text in code snippets introduces a set of concerns that don’t matter in traditional SEO, generally speaking.
Search engines like Google crawl specific code snippets that are relevant to its indexing and contextualization process. We’re talking about things like meta descriptions, canonical URLs, schema, etc.
However, AI bots can crawl code snippets that search-engine crawlers typically ignore. Within those snippets, if there’s any content that’s problematic for confidentiality, brand reputation, or other reasons, it could end up in an LLM’s dataset.
For example…
We’re talking about things like this fun little Rick Astley reference in code comments from a developer. (Yes, this is real.)

A note of caution on shady GEO tactics
Unfortunately, in this early stage of AI search, some brands are taking advantage of the fact that crawlers can access HTML content users can’t see.
Similarly to the early stages of SEO, sites are employing questionable GEO tactics like stuffing the meta keywords tag, adding additional keywords via invisible text (i.e. white text on white background), etc.
These are methods that are no longer effective - and are even considered harmful - in SEO. But since AI search is still in its infancy, it hasn’t reached the same level of sophistication as traditional search engines with regard to weeding out gamification tactics.
While it can be tempting to dip a toe in the dark arts, it’s important to remember that AI search is rapidly evolving to better serve users. As that happens, these tactics will likely become less effective and could even damage a domain’s performance and reputation in the long run.
How to audit your site for AI crawler visibility
Once you know the HTML content types that are available to AI bots, auditing site crawlability from an LLM perspective comes down to three steps:
- Compare response HTML & rendered HTML.
- Identify contextually valuable information AI bots can’t crawl.
- Identify potentially problematic content that AI bots can crawl.
Let’s dig into each step, and explore some different tools that can help during an audit.
Compare response HTML & rendered HTML.
Step one is to make sure AI bots can crawl the links, copy, media, and desirable code snippets (like SEO title, meta description, open graph) on pages of the site.
By comparing what’s available in the response HTML against what’s served in the rendered HTML, you can understand what is and isn’t available to AI bots.
That’s possible at the page level using a free tool or across the whole site using a paid crawler.
Page-level audit: Rendering Difference Engine (free)
Most websites are built using at least some JavaScript.
How much? It can vary from none to:
- A little - links in drop-down navigation menus, text in accordions and tabs, etc.
- A lot - any and all page content, links, and media (like a Jamstack site with client-side rendering [CSR]).
Because of this, you can usually spot widespread crawl accessibility errors by auditing a page from each template. If the content type is available in the response HTML for one page, it’s usually available across all of the pages that share the template.
If you’re unsure which templates are available on the site, talk to your development or product team.
When auditing a page, you can use the Rendering Difference Engine, built by your friends here at Gray Dot Co. Our free Chrome Extension identifies SEO signals added, removed, or altered during JavaScript rendering — without digging into the code.
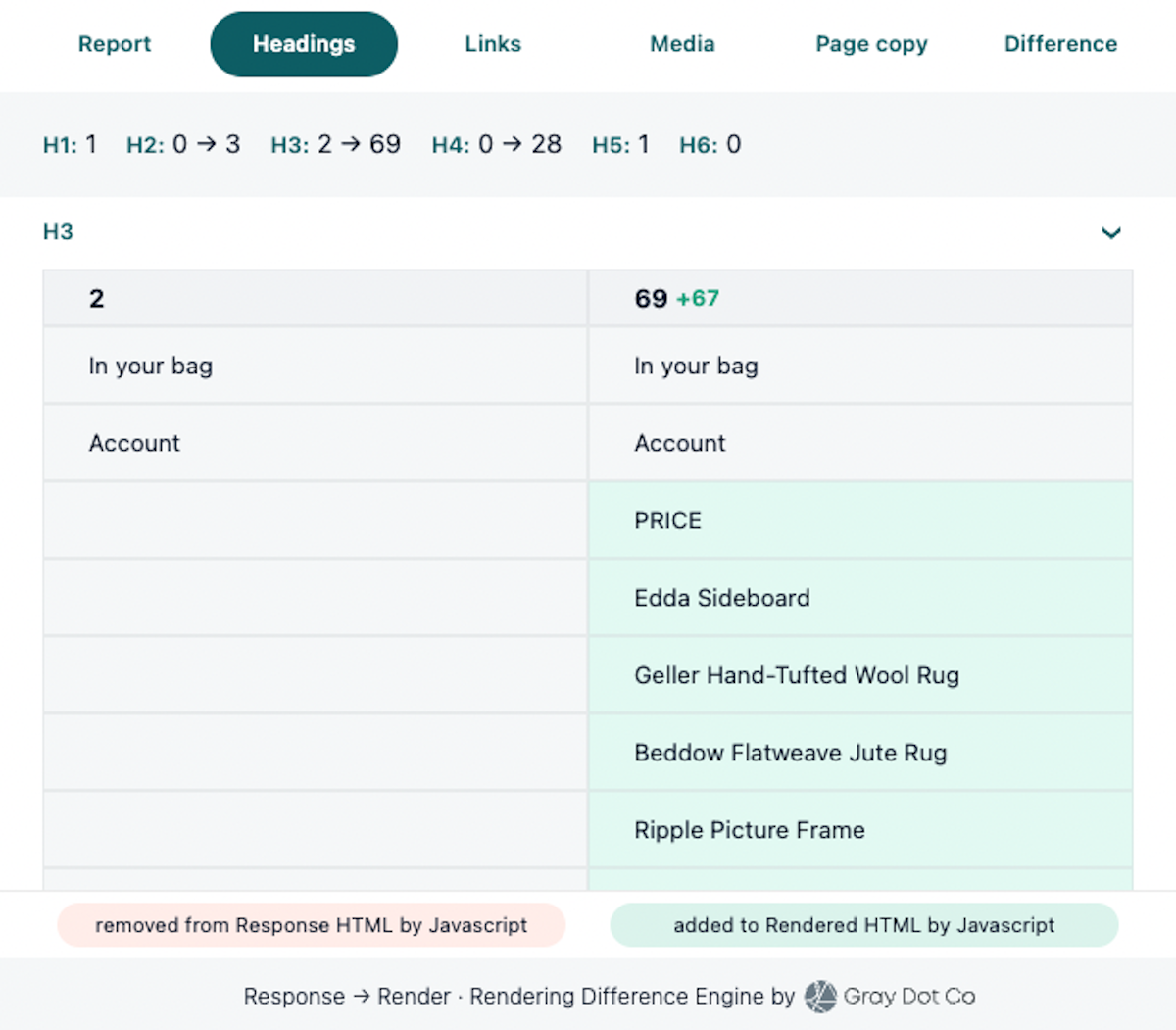
Here’s a report showing headline changes between response and rendered for the collections page example from earlier in the article. (Remember the cute candle holder?) You can see all of the product title headlines that are added as H3s in the rendered HTML, but absent from the response.
Much easier than searching for individual elements in both sets of code!
Site-level audit: Sitebulb (free trial available)
To view differences between response and rendered HTML at scale, you can use a paid crawler like Sitebulb.
Enable JavaScript rendering in the crawl settings and navigate to the Response vs. Render report in the crawl results. The report shows elements like copy and links, including how many URLs have differences between response and rendered for specific elements.
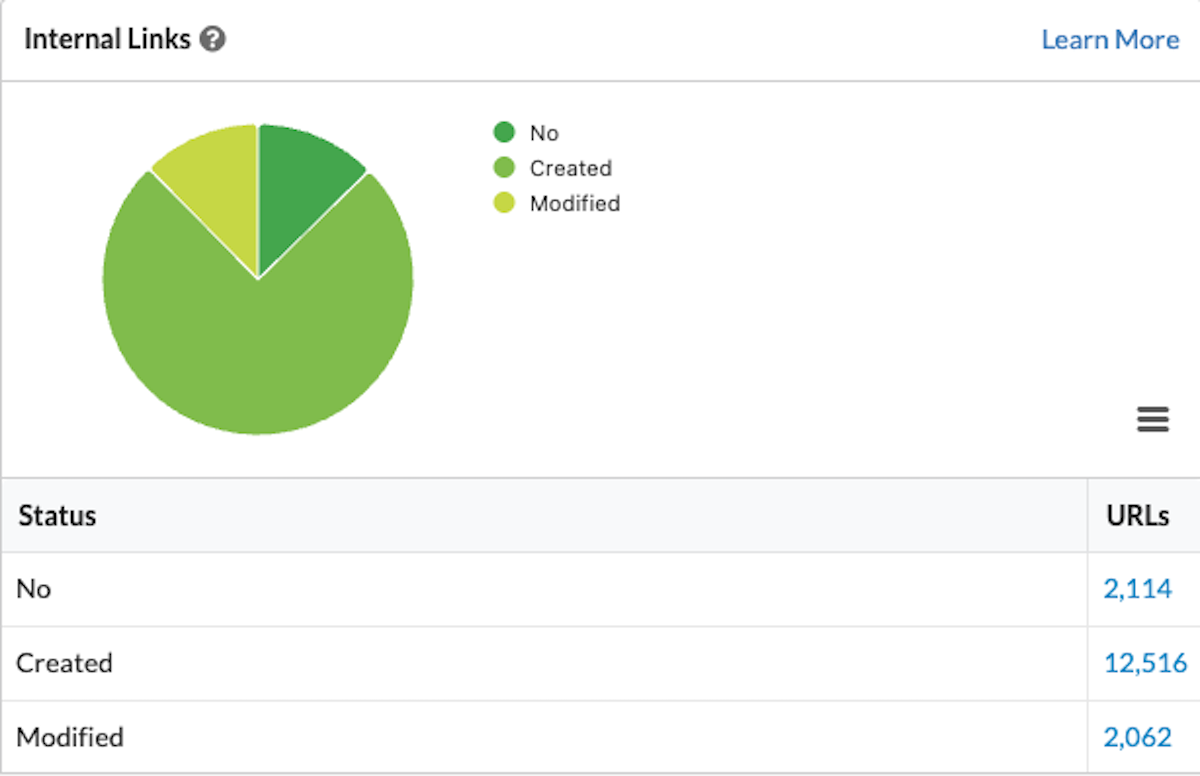
For example, in the links report above, clicking into the “created” list will show the entire list of internal links that are only available in rendered HTML.
Document any contextually valuable items AI bots can’t crawl.
You’re probably tired of hearing it by now but… anything that’s missing from response but present in rendered is invisible to AI bots.
Once you’ve used your tool of choice to identify areas of differentiation between the two sets of HTML, it’s time to gauge if what’s missing actually matters. Context missing from response HTML should be vetted to understand what, if anything, is potentially valuable context AI might use to generate brand-relevant answers.
Copy
- Important: Anchor text, headings, body copy
- Less important: Repeated brand copy, filler content
Links
- Important: Links to products, articles, or other public pages on your site
- Less important: Some external links, links to logged-in user experiences
Media
- Important: Your brand’s logo (mostly) + any original images or videos that are helpful to users trying to understand your brand or content
- Less important: Stock photography, site icons
Code
- Important: Metadata, open graph, JSON
- Less important: Code comments (as long as they aren’t problematic)
Document any potentially problematic content AI bots can crawl.
Where AI search visibility is a business goal, brands want AI bots to crawl the content they feel is valuable for their users.
At the same time, it’s important to understand whether AI crawlers are potentially picking up erroneous, undesirable, or unnecessary content.
Again, just because Google ignores certain types of code doesn’t mean that AI bots do. If any of the following types of information are in the response HTML, they could get picked up, and even worse, end up in generative responses:
- Embarrassing content that reflects poorly on the brand
- Inaccurate or outdated information that misleads users
- Confidential/proprietary information that could put your brand at risk
- Personally identifiable and private information that could put users at risk
Page-level audit: AI Difference Engine (free)
Finding problematic text in code isn’t easy, because most SEO tools only look for the code Google prioritizes for use in the crawling and indexing process.
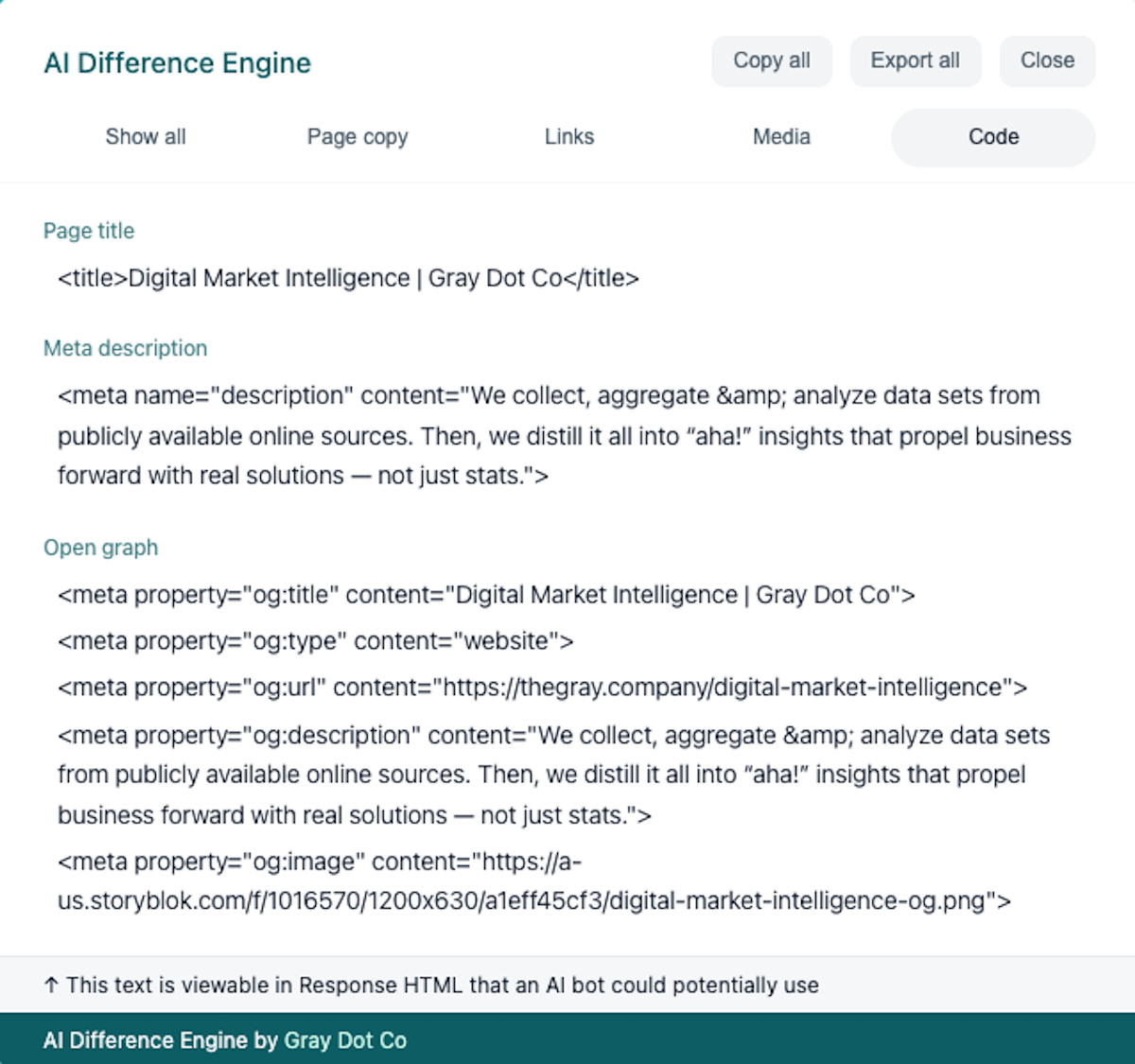
That’s why we built the AI Difference Engine, a free Chrome Extension that shows exactly what AI bots can crawl on the page. The report categorizes content by type, including a tab dedicated to any text-in-code outside of links, copy, and media.
Optimizing crawling for SEO & GEO (or whatever you want to call it)
The bad news is all of this means most SEOs now have two different sets of crawling considerations we have to take into account. The good news is, the ideal solution is just good technical SEO to begin with.
As tech SEOs, we’ve long stressed the value of serving all SEO-important elements of a page within the response HTML (i.e. server-side rendering). In fact, JavaScript powered sites that choose to serve complete response HTML generally see 30% stronger performance versus sites that require search engines to render JavaScript.
Now, with the advent and growing popularity of generative engines within the organic search landscape, that recommendation is all the more important. By including critical content in Response HTML, brands can get a visibility boost in search engines while ensuring that their content is available to generative engines.
Sounds like a win-win.

Can LLMs reference and rank your content?
Our team is here to help you find the critical site content that's missing from AI datasets.
