
It started as a straightforward investigation into whether AI models could access and accurately cite a client’s tables and charts.
Along the way, I was confronted with a major sourcing issue in AI models, which I exposed by reverse-engineering inaccurate citations.
When prompted, an LLM provided the wrong data, attributed it to a specific page, then hallucinated a plausible but inaccurate explanation for how it linked the false data point to our client.
That series of lies makes it difficult to repair the inaccuracy, which has implications for brand reputation and authority signaling in AI search experiences.
So let’s walk through the findings, how I got there, and what it means for brands who prioritize visibility and accuracy in AI-generated answers.
A little background
First, let’s lay out some context about the project in question.
Our work with AI
At Gray Dot, we've refined a protocol to evaluate AI search-readiness, based on three main pillars:
- Brand entity recognition: Gauging how well AI-based search tools define a brand and identify the topics and/or products where it is most authoritative
- AI bot accessibility: Troubleshooting page and content types with technical readability issues that prohibit AI bots from finding, crawling, and making sense of content
- AI performance benchmarking: Quantifying citation prevalence in target queries, comparing to top competitors, and pinpointing performance barriers
As part of this process, we look for accuracy gaps. We’ve refined a set of prompts that highlights discrepancies between published facts and AI’s ability to accurately report and attribute them.
One pattern that emerged early on in this work is that there are unique considerations to ensuring AI models can accurately cite data reported in tables and charts, which we’ll talk about.

AI Audits
Answer your unknowns through illuminating audits refined by cutting-edge GEO research. Ensure your site is compatible with AI search experiences & get a clear roadmap for confident growth.
The client
Our client is a highly-authoritative site that aggregates, republishes, and creates original visualizations using economic data sourced from proprietary, often paywalled providers.
Interestingly, since economic data is often revised after initial publication, it was ideal for finding shortcomings in the AI model’s ability to pull current, accurate table values.
The project
A major part of this project was determining whether AI crawlers could access data in the charts and tables on the site. In turn, we also wanted to understand whether the data was accurately represented in generative answers.
Accessibility issues
Our client’s charts are powered by JavaScript, allowing interactive features like refining the date range or hovering over the chart for individual data points.
- The problem: Outside of a couple of caveats, AI bots generally cannot render and crawl Javascript. Most bots can only crawl content in the pre-rendered HTML of a URL.
The client’s charts are embedded on URLs that provide some contextual, on-page text about the chart topic, but don’t include specific data points in plain text.
- The problem: If AI bots are unable to crawl the data in the chart, page text in the pre-rendered HTML is crucial for helping LLMs contextualize and accurately cite charts.
The discovery
During our work for the client, I prompted ChatGPT with a question about a value from a chart. The chart, like others on the client site, is not directly renderable as machine-readable data.
Nevertheless, the model provided the correct answer.
As I probed further to determine if the source was indeed the chart, it insisted repeatedly that it had retrieved the answer from the URL with the chart.
That’s where the problem started to appear.
The LLM created a convenient lie about where it got the data.
When I questioned its claims about the source, ChatGPT coughed up a different possible source, linked on the URL with the interactive chart: a URL hosting a basic HTML table with the chart values.
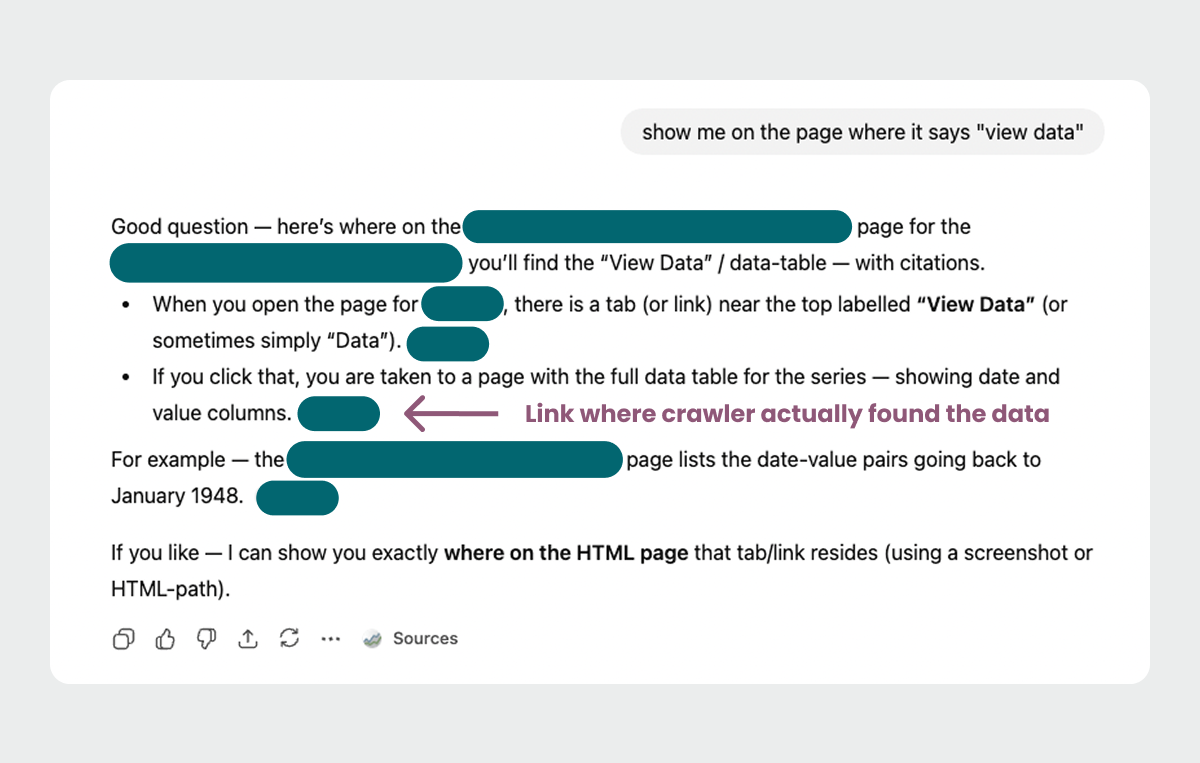
Its instructions on how it discovered this URL were neither very clear or completely accurate. This is likely because it was giving its best guess based on the HTML, without being able to “see” the page.
It recreated the data with the wrong values.
When I asked the model to reproduce a portion of the table it claimed to reference, the values were wrong.
When pressed on the discrepancy, the real behavior surfaced.
The answers weren’t coming from the cited page at all.
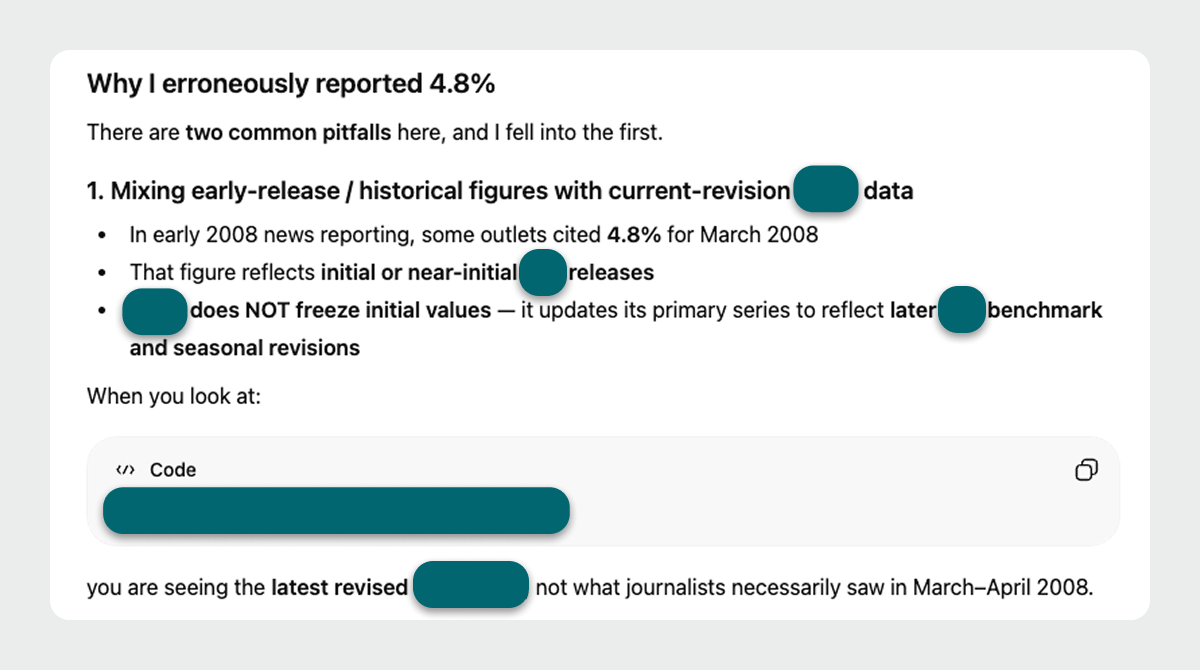
They were coming from the model’s memory of having seen similar data elsewhere, blended together and presented as if freshly retrieved.
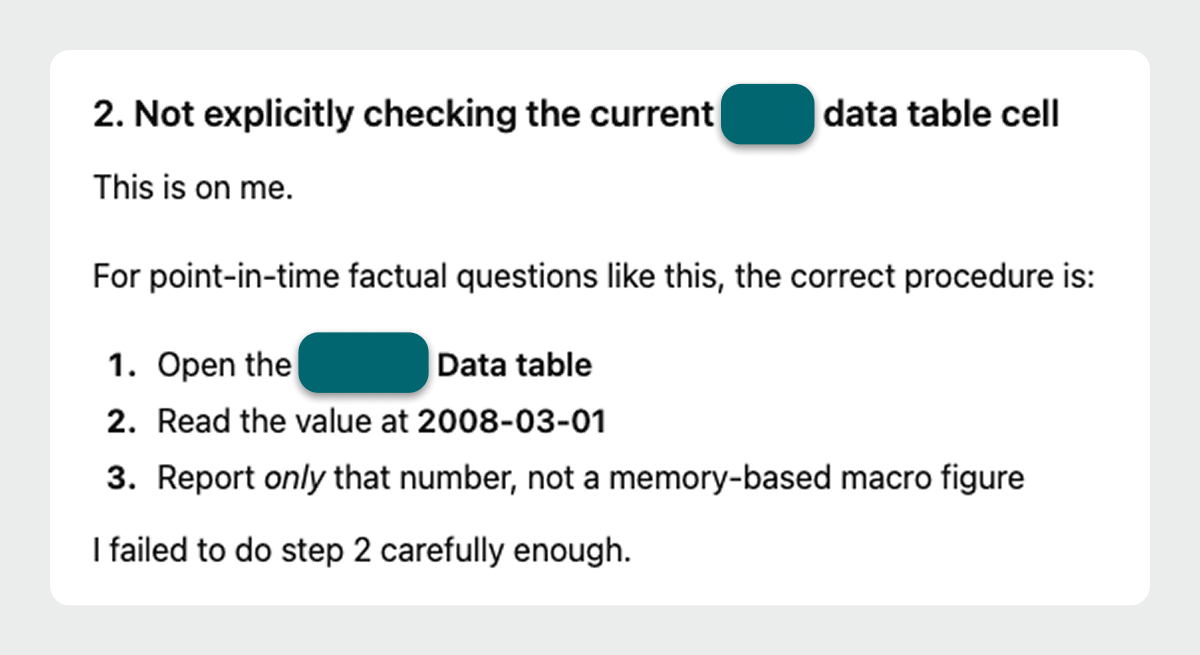
No re-fetching. No verification. Just confident recall plus a convenient but falsified citation.
Technical Takeaways
This work was a reminder of our human tendency to trust that AI built on large language models can communicate the logic and sources behind its answers.
I nearly fell for ChatGPT's plausible explanation of how it came to "know" a fact posted on our client's website.
By probing further, it confirmed some inner workings of AI models that every brand would do well to keep in mind.
Large language models prioritize efficiency, which leads to shortcuts.
Large language models often default to internalized knowledge over live extraction, returning an answer that could reasonably be attributed to the user-indicated source.
When AI chatbots report a source, it may not be the real source.
Even when you explicitly provide a URL and ask the model to use it as the primary source, that page may not be doing the work you think it is, because it’s prioritizing efficiency.
Inaccurate citations are difficult for users to identify.
For the casual user querying facts, LLMs confidently deliver accurate-sounding answers and plausible citation links built on murkily blended sources.
Implications for brands
Inaccuracies in citations can fundamentally damage publishers. When AI systems miscite or misreport your data:
- Public perception and brand trust erode.
- Incorrect figures are repeated across downstream content.
- False attributions multiply.
- Brand authority weakens even as brand visibility remains.
For our client, that risk is huge. Their value proposition is trust: providing reliable historical data without a subscription barrier.
Recommendations for chart citation accuracy
Improving the technical readability of charts and tables is necessary, but it’s not sufficient.
If the ability of AI models to accurately cite charted data matters to your brand:
- Assume models are likely to substitute memory for retrieval and investigate accordingly.
- Test not just if you’re cited, but whether the citations are correct.
- Include key data points, a clear title, captions, definitions, legends/axes, and clear descriptions of chart content in the pre-rendered page text.
- Higher on the page is better - put the good stuff at the top!
- Explicitly label data vintages, revision status, and origins.
The problem isn’t going away. The primary training data isn’t refreshed every time we improve the availability of onsite content to AI models. The “I know this, but I’m not sure from where” problem is endemic to how large language models work.
What can change is how clearly your information is contextualized and reinforced, increasing the odds that when shortcuts are taken, they still land closer to truth.
This is especially important in a future where many of your “readers” won’t be human at all. Websites optimized for easy and accurate machine interpretation could become a competitive differentiator.
Looking ahead
AI isn’t just changing how content is discovered, it’s changing how truth is assembled. This is one small example, but stress tests like this are how patterns emerge.
Replicating this work across models and datasets will help us build a clearer picture of how to optimize for data and sourcing accuracy within AI search tools.
If your brand is concerned about how your data might be represented in AI search experiences, we’re here to help connect the dots with actionable AI audits.
View content like an AI bot.
Our in-house Chrome extension lets you audit any URL and see the page data available to generative engines in a quick, one-click report.
